“Natural” IF Interfaces May Be Closer Than You Think

Speech is natural between people, it may now also be close to being natural with computers too. Creating a natural flow between the player(s) and the story reaches for cutting-edge embedded technology employed with computer design principles stretching back nearly 70 years.
All early mainframe systems employed a system of “dumb” terminals connected to a large central server who’s only task was to process requests from the users entered through the striped down interface of the connected screen and keyboard:

Computing power has ebbed and flowed from the mainframe to the “edge” clients over the years. Sometimes (as in the case of a ‘local’ terminal on a Linux PC) the two reside on the same machine. The screens today are larger and full color but for large-scale processing we still access mainframes from “dumbed-down” computers.

Applying the proven “dedicated” compute model to IF may be the best method for achieving interactions with IF that are nearly as natural as talking with a friend. It may be cheaper to build a server/terminal IF system besides.
IBM broke with the ‘traditional’ integrated PC designs of the day with the compute unit separate from the I/O, specifically the keyboard and mouse.

The IF design calls too for the separation of I/O from processing and I was delighted to find that the separation actually turns out to be cheaper to make!
The Dedicated Voice Keyboard
Consider this embedded platform device, the STM32 ‘HUZZAH32’ as the base voice I/O platform:


This little board clocks in at around $20.00 and comes complete with battery interface and charging circuit, capacitive touch, and plenty of I/O pins including I2s, wifi, etc. It is in short all you need to interface with a microphone array and stream the input to an (optionally) dedicated server or PC running an IF virtual server. This board features “I/O a-plenty” and is a great development platform for new ideas along the building path.
Meanwhile, new microphone technology is cheap, compact, and requires only simple circuitry. For for these “few bucks” they’re accurate enough to detect a gunshot and it’s direction from 100’s of meters away.
Imagine, then, this little device housed in a brushed metal case with a slim battery and a printed microphone array based on these I2S microphone breakout boards. The device streams the voice input to the central server. What you have, then, is a universal speech HID that fits nicely in the palm of your hand.
The server may also be embedded. Since the server acts as a dedicated voice processor device and IF interpreter server we don’t care about anything but a server’s core functionality. Since we’re not tangling with I/O on the server we can get away with a cheap Orange Pi Zero Plus 2 or similar costing for around $25.00.
We don’t need even for a dedicated embedded server; a virtual machine running on a PC will do nicely. You get the speech processing power of the PC interfaced with your portable “speech box.”
We tell the server about the mic’s array placement with the Pulseaudio module module-echo-cancel for excellent noise-cancelling audio processing. Quality voice input, I (re)discovered, is more important than the recognition software for good results.
The dedicated Speech/IF server runs only the following:
- Speech processing daemon (PocketShynx or Tensorflow)
- IF web interpreter
- proxy server
The proxy server serves an ‘open’ wifi network and directs the player’s browser directly to the IF web parser on connection. This is similar to the TOS page you first see when you connect to a Starbucks wifi making connecting to the game from your phone effortless.
What the architecture really affords is opening the experience to several people around the table. Each person has their phone stood in front of where they’re seated. They can pass the speech device among them at will. This would be especially true if the device also contained a camera whereby players could look at augmented reality images either in their book or on the map spread across the table.
I’m going to take off from here using my book-based IF concept.
Print and Play
So now everyone has their well typepset book with tabs (created in LaTeX and possibly ‘psnup’ for signatures), their phone, and a map in the middle of the table. Each player’s phone displays the parser view and their books are chock-full of all kinds of information (and parser output).
We bundle the PDF for the player to print ahead of the game, “cheap and simple.”
I’ll use ‘Game of Thrones’ for this example. Now, I’ve never seen GoT except for the clip where the little guy declares a dual with his accuser by “blood rights of his house” or whatever.

Okay, so here’s the map spread across the dining room table, you can use a marker to designate where you (think) you are:
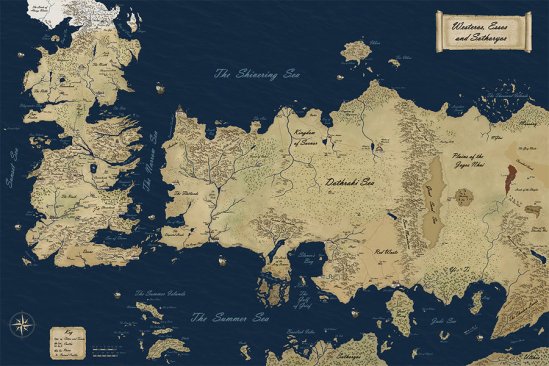
The book contains an inset map outlining the interior of the court chamber. You witness now the proceeding and decide the accused’s guilt:
say, “down with the little guy!”
“Order! Order!” Exclaims the judge, “we shall have silence! One more utterance and I shall have you thrown in the dungeon!”
Now, maybe you pipe up again and get thrown in the cooler. Maybe the guard winks at you and the game takes on a whole another genre, if you’re into that sort of thing. Who knows?
Okay, back to the main map, your posse decides to turn North and you see this:

So you explore around (possibly with a camera module in the speech device and augmented reality enabled with Javascript on the server)–a transparent overlay tells you where you are followed by a typographic dagger indicating objects if some are to be found. Descriptions for all this is found in each player’s book. Examining objects, for example, may render a 3D model to turn around and look at to your heart’s content.
Many other opportunities, like a D&D like setting where the DM gets a supplemental printed manual may be had. The mix of player dynamics is wide and all this may be done through speech alone.
So there you go, what do you think?
By the way, special thanks to Hanon Ondricek for getting me thinking in this direction.


{kind=link}
{kind=link}