What starts out as jkj yuio and I pinging ideas off each other about a hardware design for a speech interface morphs now into a design discussion about full-on modeled IF worlds.
Meanwhile, as I am a big fan of Literate Programming I asked Linus Åkesson about the idea of enabling Javascript hooks with return values in Dialog. Linus responded,
This, of course, annoys me to no end because I want to “play about” with all kinds of snazzy features not found native to IF languages but ultimately I concur with Linus’ ‘adult’ assessment.
In the world-modeling thread jkj youio points out that any attempt at doing so requires an Upper Ontology, that is, a kind of ‘backbone’ running through our simulated world that connects the fee-form story environment to the ‘housekeeping’ of the IF world model. He writes (emphasis mine):
This is the backbone of your information model, whether it’s statistical or symbolic. You need a fundamental set of semantic references on which to build and to exchange information.
Otherwise you can never represent anything because you haven’t defined what you’re talking about.
I’ve always thought the very base ontology has to be created manually. After that it can be added to by automation, learning and pattern processing. In this respect the system is not entirely the product of corpus digests, but also a “kick-started” manual core.
What follows is a draft proposal for creating an Upper Ontology using Dialog. I chose Dialog 99% because Linus’ design is flexible and 1% because while he’s certainly correct about the inherent problems with external process hooks my “inner child” is a bit sore. That is, I’m about to give Linus a “pleasant headache” by using Dialog in a way he may not have imagined. I’ve had developers use my systems in ways I never imagined and I love them for it.
First for the “manually created base” I’ll use “Rambles in the Mammoth Cave, during the Year 1844” by Alexander Clark Bullitt. This book is great because Mr. Bullitt parses the cave into neat areas with vivid descriptions. Here’s an excerpt from the area known as “Annetti’s Dome:”
Descending a few feet and leaving the cave which continues onwards, we entered, on our right, a place of great seclusion and grandeur, called Annetti’s Dome. Through a crevice in the right wall of the dome is a waterfall. The water issues in a stream a foot in diameter, from a high cave in the side of the dome—falls upon the solid bottom, and passes off by a small channel into the Cistern, which is directly on the pathway of the cave. The Cistern is a large pit, which is usually kept nearly full of water.
Near the end of this branch, (the lower branch) there is a crevice in the ceiling over the last spring, through which the sound of water may be heard falling in a cave or open space above.
A quick semantic keyword analysis yields:
| Weight | Word | Tag |
|---|---|---|
| 11,718.021 | Cistern | locality |
| 11,718.021 | Annetti 's Dome | locality |
| 11,718.021 | Cistern | miscellany |
| 11,718.021 | crevice | noun |
| 11,716.053 | dome | noun |
| 6,586.603 | cave | noun |
| 2,342.013 | waterfall | noun |
| 1,063.467 | pathway | noun |
| 323.569 | pit | noun |
| 193.349 | stream | noun |
| 137.541 | bottom | noun |
| 118.796 | water | noun |
| 76.156 | wall | noun |
| 64.997 | channel | noun |
We can write semantic algorithms for ‘localities’, etc. but for simplicity in this example we’ll just grab the objects. I’ll use ‘waterfall’ here.
I suppose the best approach for converting prose into Dialog is by running the objects first against the vectorized corpus of the itself then through generalized vectorized corpuses like Wikipedia or Common Crawl. The word comparison (among other) process is calculated as a weighted average favoring the prose’s corpus.
It’s constructive to look at this word comparison graph from GloVe’s github page:
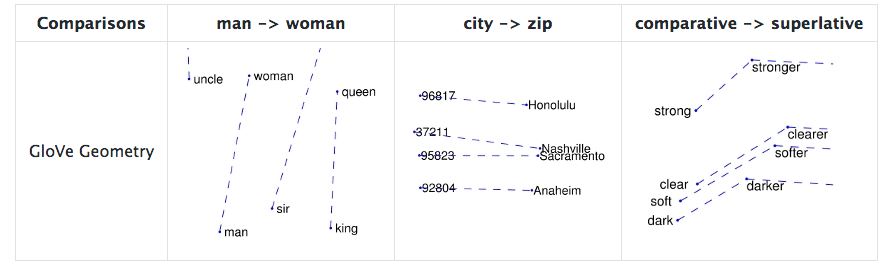
Words closer to each other means that they’re more closely related. For each object (waterfall) we ask all the questions Dialog wants to know. We can even add definitions of our own dynamically (cold):
|Property|Result|
|—|—|—|
Heavy|Yep
Moveable|Nope
Container|Nope
Cold|Yep
Supporter|Nope
…|…
Presuming a high degree of accuracy (it’s reported to be ~90%) we potentially do word relationships and export the results as Dialog code
#annettis_dome_waterfall
(name *) waterfall
(cold *)
(descr *) Through a crevice in the right wall of the dome is a waterfall. The water issues in a stream a foot in diameter, from a high cave in the side of the dome—falls upon the solid bottom, and passes off by a small channel into the Cistern, which is directly on the pathway of the cave.
(* is #in #room)
So that’s basically the idea: take each object in a text, run natural language analysis on it with emphasis on the attributes Dialog wants to know, and exporting Dialog code.
I know that even the prose I sighted (will GloVe be smart enough to know that ‘foot’ is a measurement?) has it’s problems. Experiment with the incoming prose may reduce these issues as well as tweaking the word relationship analysis model.
I can see perhaps that instead of “shoving” the source book into the vectors the author makes edits based on experience. The input text may be written suited for relationship analysis in the first place.