If streams 5 and 6 both suppress output to other streams (I assume), which one take priority?
I’m not sure about that… (I never did it myself) @Juhana hopefully knows.
If I understood the question correctly, the implementation always closed other streams before opening a new one so the issue never came up.
In that case, I’ll just pick one.
I agree with not adding a general Glk opcode. The objective for a Z-machine spec is to document how Infocom designed the it, not add on new features. By allowing for bigger games, the V7 and V8 extensions, really didn’t do that.
While I agree that documenting Infocom’s design is a very important part of the Z-Machine Standards Documents, even the 1.0 spec added features not intended by Infocom (not including the two new versions). The Unicode translation table and multiple output stream 3 are the two that spring to mind. In addition, the standard is clearly written with the idea of adding features to future versions in mind.
I can’t deny that interest in the Z-Machine, and especially in modifying the standard, has gone down since the late 90s, but personally, I’d like to keep the Z-Machine alive, and I have… plans… in that direction.
1 Like
If any extensions to the Z-Machine are being specified (and they clearly are) then I don’t really understand the opposition to a Glk opcode. Reality is that many Z-Machine terps already run through Glk. Specifying one opcode would then give those terps free access to hyperlinks, the system clock, graphics windows, and more.
On the other hand, no one has been asking for it, and if the private use area is added then people could add it themselves if they wanted, and if it was used, it could be specified later. But I don’t think ideological opposition to it is warranted if any other features are added which only some terps will implement.
Another feature which could make a difference is a bigger jump opcode. That would have made Dialog’s implementation simpler and more efficient I think. But now Dialog has the Å-machine to target.
1 Like
Glk is a complete interface system designed around an idea of how IF systems generally work. Glulx doesn’t have its own interface system, which is why it needs opcodes like the Glk opcode. The Z-Machine, on the other hand, does have its own interface, which even in versions other than V6 is technically incompatible with Glk, although of course some minor hackery can allow for most Z-Machine features to be well supported in a Glk-based terp.
Andrew Plotkin has, elsewhere on this forum, said ‘it is not a goal of Glulx to replicate every feature of the Z-machine’. I believe this to be the correct decision. While Glulx may have been designed as an alternative (or indeed replacement) to the Z-Machine, it was deliberately not designed to be particularly similar. In addition to this, Glk is based on Andrew’s idea of what an IF interface should be, in the definite knowledge that it did not quite match what the Z-Machine’s interface actually is.
I don’t want to give the Z-Machine two slightly incompatible interfaces (in the case of V6, wildly incompatible). If the Z-Machine wants to add Glk-like features, it should do it in a Z-Machine-like manner.
1 Like
On the subject of graphics (in V5, since they’re already available in the poor unloved V6), well, Infocom’s XZip spec has a way to do that. I’ve avoided suggesting this be added to the main text of the Standard because I’m not really sure how well it would work. It shouldn’t be too difficult to add support for it to Viola in order to test it. I’ll maybe give that a go soon.
Coming back to the topic of supporting the full Unicode range of characters: Currently, the interpreters I know best (frotz and my version of jzip) store characters as UCS-2 sequences. However, going from this to UTF-16 is not a large step. I made a quick hack to test it and it works (with lightly modified David Kinder’s unicode test):
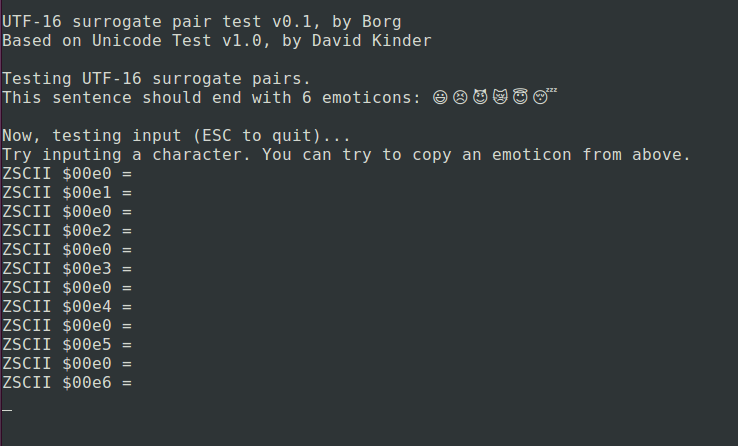
The emoticons are in the range U+1F600 to U+1F604F and encoded as surrogate pairs, each part of the pair a separate ZSCII character: $e0 is the high surrogate for all and $1 to $e6 the low surrogate for each of the 6 emoticons. On input each surrogate pair is similarly returned as two ZSCII characters.
Output even works in unmodified windows frotz (but not input):
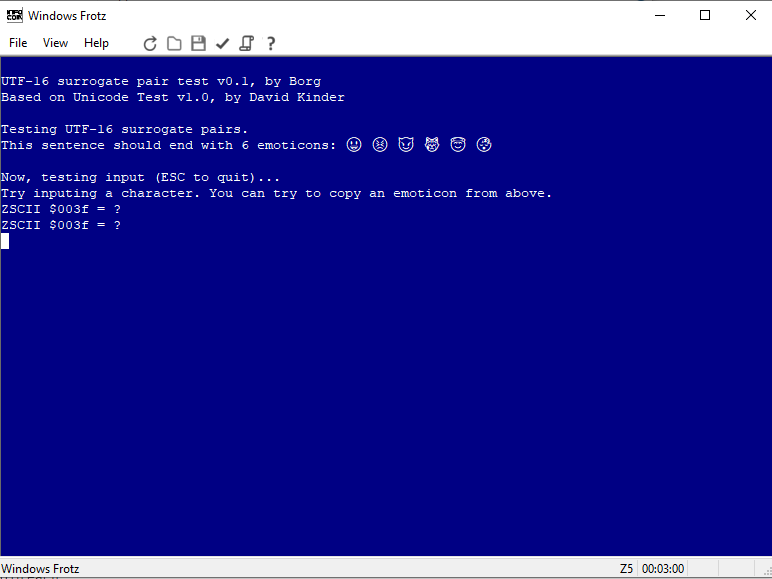
Test program and source attached:
smileys.z5 (4.5 KB)
smileys.inf (1.7 KB)
1 Like
I hadn’t considered it would be possible to hack UTF-16 into the current Unicode translation table. I do think having input return two characters is not great, though. I think instead altering the Unicode translation table to understand UTF-16 (so that characters in the table may be one or two words long) would work better, and shouldn’t be too difficult for interpreters to handle.
This approach works nicely:
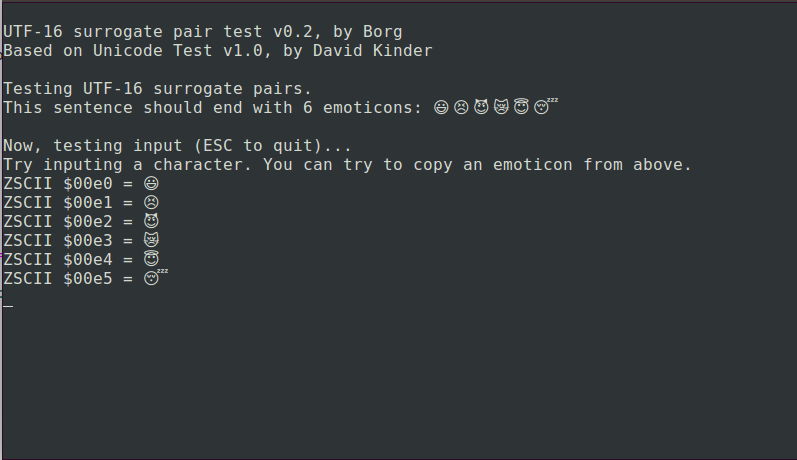
What I don’t like is that it requires a linear scan through the Unicode translation table for every ZSCII character >= 155. A faster but more wasteful approach is to allocate 2 consecutive ZSCII values, one for each part of the surrogate pair, with direct use of the low surrogate undefined. This way direct indexing into the table will work.
Hmm. I see what you mean about the linear search there. I don’t really want to waste two zscii characters for each of the larger Unicode values, though. I’m toying with the idea of separating the codes with surrogate pairs into a different Unicode translation table, or maybe just require that they go at the end of the main table, and have another word in the header extension table that gives the address the two-word Unicode translations start at.
I like the idea of restricting the surrogate pairs at the end of the table. However I would suggest to keep the high and low surrogates separate: The high surrogates go before the end of the table and the low surrogates go after the end, with a new word in the header extension giving their count. There are two reasons for this:
-
The main one is compatibility: An interpreter unaware of this extension will not create random pairs (which may be printed by e.g. windows frotz) but only see high surrogates.
-
A secondary consideration is that the stepping of the table will be constant, simplifying the code for translating to and from ZSCII .
If I’m understanding this correctly, if the high surrogates are at the end of the table, and the low surrogates are directly after the end of the table in the same order, there’s no need for the header extension to contain the address of the low surrogates.
The low surrogates are at byte address (unicode extension table address) + (2*unicode extension table length). It’s also easy to work out where a low surrogate is relative to any high surrogate. I think this works nicely.
I don’t understand this - my idea was to have the regular table length (len) and the number of surrogates (num). Then the pairs are (table[len-num],table[len]) to (table[len-1],table[len+num-1]). You do need to also know num.
You can get around this by storing the low surrogates in opposite order, so the pairs are (table[len-num],table[len+num-1]) to (table[len-1],table[len]).
Okay, right, I was getting something a little wrong there. If you put the high surrogates at the beginning of the table instead of the end, the position for the low surrogates becomes table[highpos+len], yes? That might be cleaner.
Sure, but this way you can’t keep the default Unicode translations (ZSCII 155 to 223). Let’s see if anybody else has a suggestion.
The Z-Machine is a 16 bit machine, designed long before Unicode. We can come up with lots of potentially cool additions to the design, but something like this will just be fighting the bit width the whole way. Supporting multiplane unicode is unnecessary and an anti feature IMO. Multi plane unicode is why we have 32 bit VM alternatives now. If people are after programming challenges there are lots of ones out there that will have a much clearer direct impact on IF authors and players.
I don’t disagree, but I’m adding some UTF-16 support anyway, so if it is useful to others I don’t see a problem agreeing to a common subset.