Coming back to the topic of supporting the full Unicode range of characters: Currently, the interpreters I know best (frotz and my version of jzip) store characters as UCS-2 sequences. However, going from this to UTF-16 is not a large step. I made a quick hack to test it and it works (with lightly modified David Kinder’s unicode test):
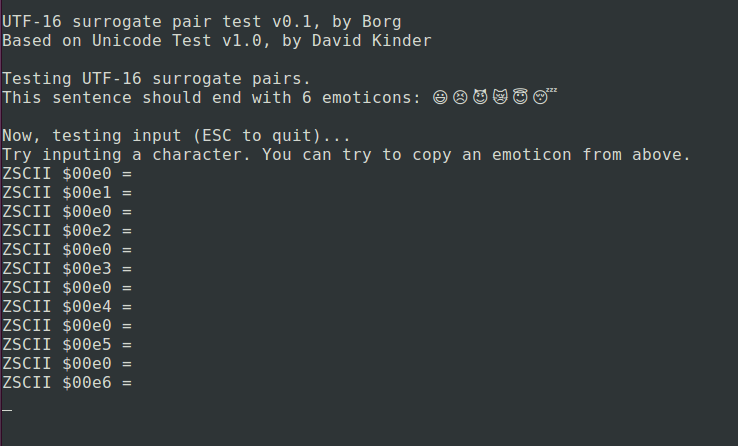
The emoticons are in the range U+1F600 to U+1F604F and encoded as surrogate pairs, each part of the pair a separate ZSCII character: $e0 is the high surrogate for all and $1 to $e6 the low surrogate for each of the 6 emoticons. On input each surrogate pair is similarly returned as two ZSCII characters.
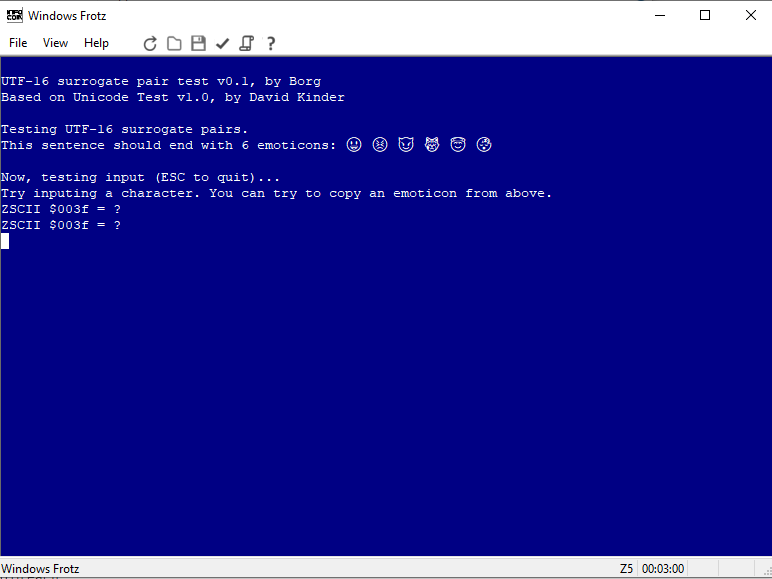
Output even works in unmodified windows frotz (but not input):
Test program and source attached:
smileys.z5 (4.5 KB)
smileys.inf (1.7 KB)