I generally avoid LLMs, because the sorts of things I do (programming, writing, research), either they’re very bad at or I enjoy doing it myself. I imagine at this point my stance on their use for IF is well-known.
But if I’m teaching students about how they work and what they’re good and bad at, I figure I should also have firsthand experience using them for actual tasks, not just basic demos. I currently have some tedious language processing that I would love to automate, and in this case, it seems like LLMs would be the right tool for the job.
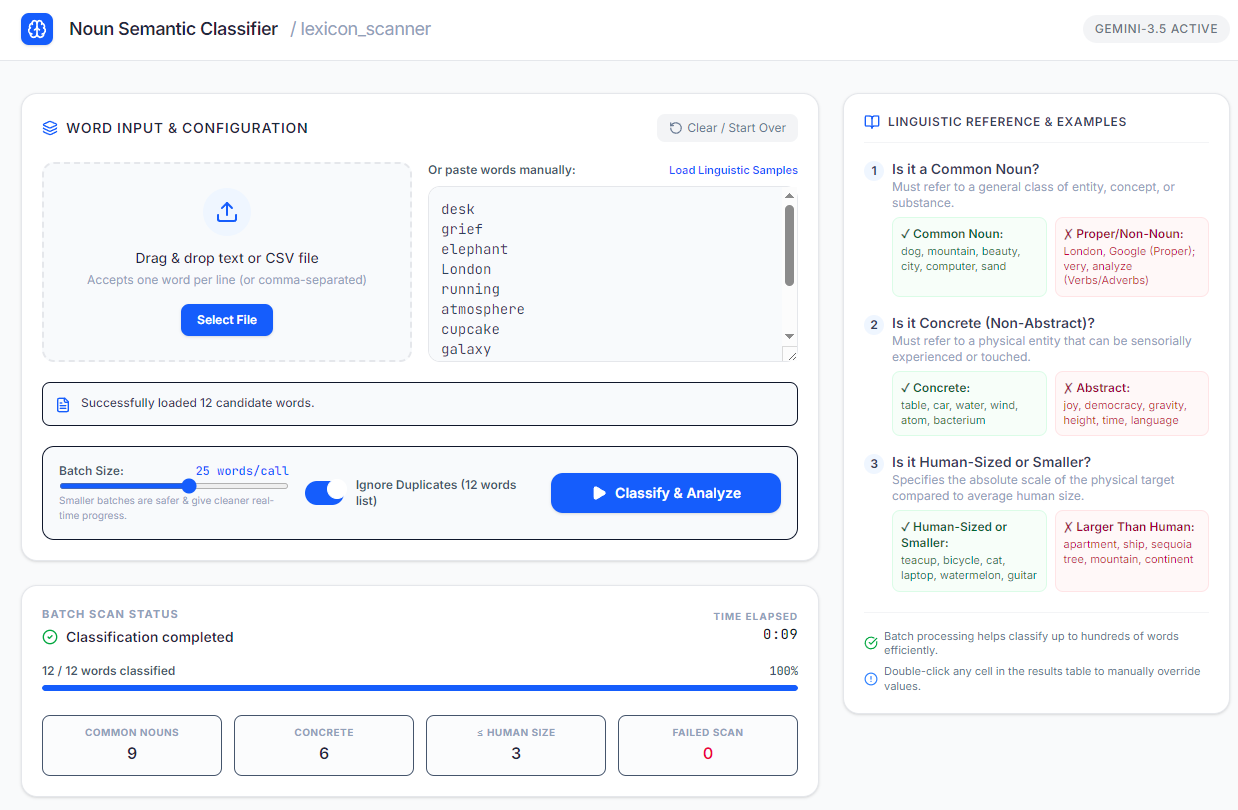
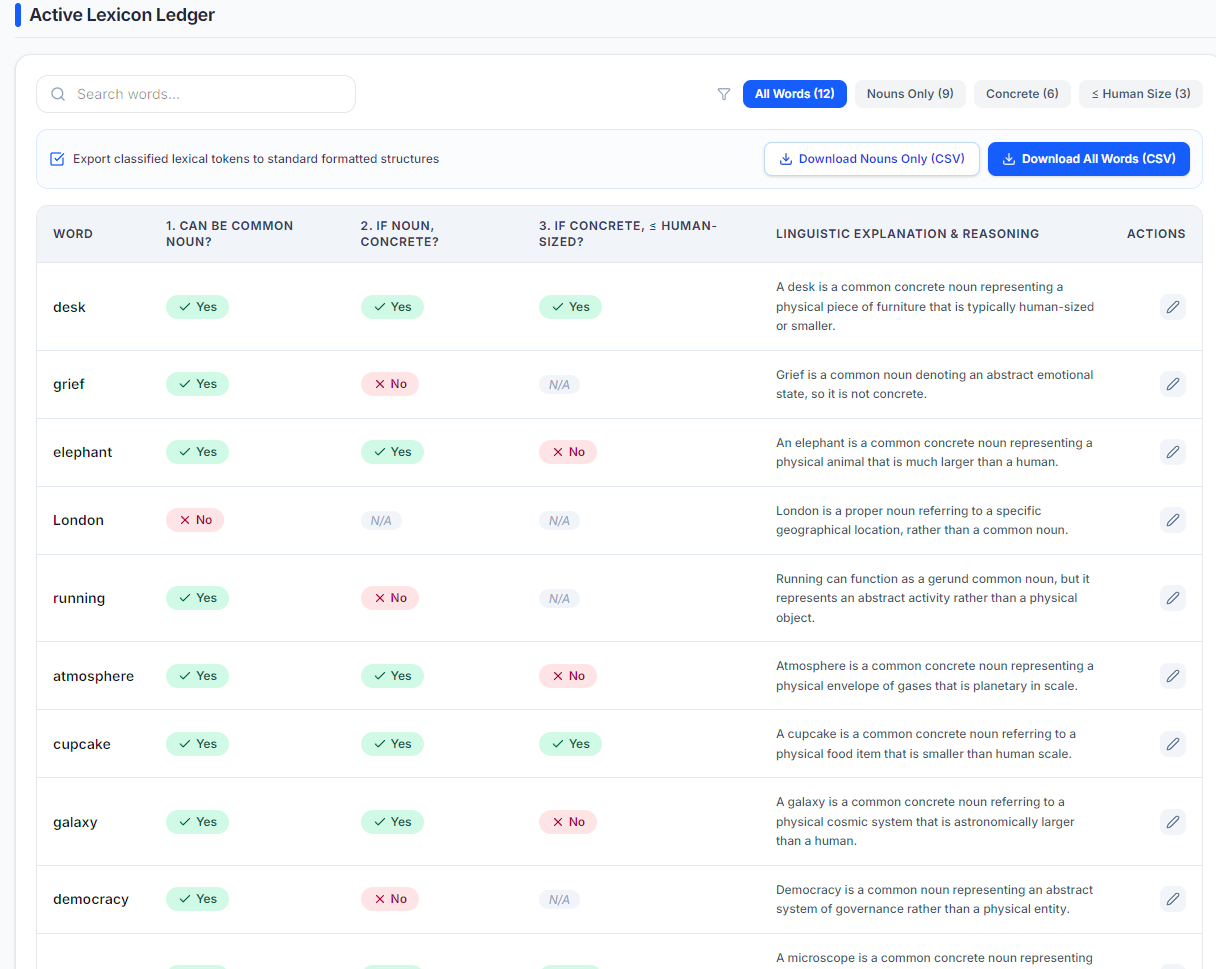
Specifically, I want to take an enormous list of words (4.5 megabytes of plain text) and make a spreadsheet giving semantic properties of each one. For example:
- Can it be used as a common noun (that is, not a name)?
- If so, can it refer to a concrete object (that is, not something abstract like “joy”)?
- If so, is that concrete object human-sized or smaller?
- Can it be used as a common adjective?
- If so, can it apply to concrete objects?
- And so on…
This seems like a promising job to automate. It involves analyzing words based on their contexts of use, and it’s tedious enough that no human would want to do this for four hundred thousand individual words. And if there are mistakes, it’s not the end of the world.
But…I don’t really know where to start. Are any of the LLM companies still offering use for free at this point, or are the serious models now all locked behind paid APIs? OpenAI’s “compare plans” page is frustratingly vague on what’s actually possible on a free plan. Firefox claims to have a sidebar for easy LLM use; can I turn that on without inviting endless privacy violations? Which of them will accept a 4.5MiB text file?
Basically, if I want to (as a complete novice) try using LLMs for some language-processing tasks…where’s the best place to start, in mid-2026?