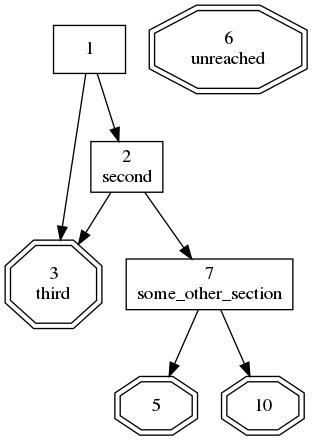
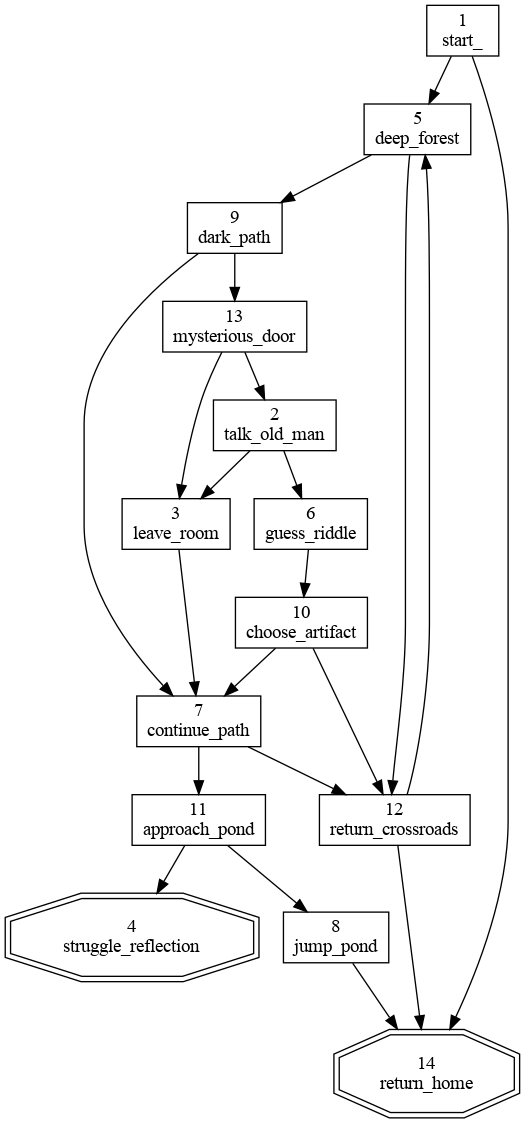
Pangamebook is a free filter I wrote for the (also free) Pandoc document conversion tool. It shuffles and numbers sections to create (static) gamebooks. So this is for choice-based IF that can be represented on paper, or in a EPUB, but not for those fancy scripted books where the computer keeps track of stuff for you. It also comes with a second script called pangamebookdot that generates a DOT file for Graphviz, so you can visualize how all the sections in the gamebook are connected. All is explained in the README, at least in theory.
If this sounds vaguely familiar it is probably because of the (equally cleverly named) gamebookformat tool that I posted about here a few years ago. That one was much more complex as it had its own configurable template system for various output formats. Pangamebook building on top of Pandoc is a much more sane approach to do the same thing. There are a few advanced features of gamebookformat that are not in pangamebook (yet?) but I think the only must-haves to layout a gamebook are included and other than bugfixes I have no further plans for it.
Thanks! I just pushed a small bugfix. The README mentions that there is an error to use a hardcoded section number that is too low, but in reality there was no error (it just caused the section to be assigned a higher number than the intended). Now it will hopefully work as intended (i.e. it will crash and tell you you did wrong instead of just silently accept the wrong number).
And yet another small bugfix. The graph output included boring automatically generated section names like “section-1”, “section-2” etc that were added for sections with hardcoded numbers. Those are hidden now. As a bonus made the graph nodes look slightly prettier by adding a new-line between number and name.
I have not kept this thread up to date. There has been a few more updates. Today I posted version 1.4.0. Compared to back in October 2021 the main thing that changed is that the graph output is better now. There was probably a few bug fixes as well.
The goal was always to make this tool as minimal as possible and avoid updates. I have a plan to improve the section shuffle algorithm, probably call it version 2.0.0, and hopefully only fix bugs after that, as the filter already does what it needs to do.
Does your tool handle fitting sections to pages in such a way as to avoid page breaks within them? That’s one thing I never managed with GordianBook, because the algorithms for satisfying so many constraints were beyond me.
No, that is beyond the scope of the tool. I can see how it would be useful, but when pangamebook is applied to the document that is before any output layout is known, and the same section order would be used even if multiple output documents in different formats are generated.
It is possibly possible to mark up sections in some way to avoid splitting them over page-breaks, and it might make sense for the tool to have some setting for that. But that would leave the problem of some pages ending with long blank gaps (whatever the correct typography term for that is). It would require manual fiddling and maybe inserting filler images to work around that. I do not think it would be possible to solve it automatically.
When making PDF output through LaTeX there is a good chance that some good workaround exists, since TeX was made precisely to autmate boring things like positioning page-breaks appropriately. It is rarely perfect, but often good enough, so with the correct inlined LaTeX it might be possible to get quite good results.
I always imagined that if/when someone got to the stage of actually publishing/printing a book there would be manual work needed anyway to get everything just right. Worst case even mess with the order of sections.
To get better results from the tool itself it would have to somehow analyze the generated output (e.g. a PDF file) to see where the page-breaks ended up, and then try to re-order sections or/and insert page-breaks and generate a new document, probably iteratively many times. Now that I think about it someone could try to do that as a wrapper around pandoc re-generating the gamebook with different random seeds and look for the best possible output. But it sounds far from trivial to get right.
This is what I have to do in Gordian, move sections around to try and minimise the gaps. I do, however, have a hint that a section should be allowed to split across gaps, otherwise each section is set not page-break inside.
What I toyed with, but couldn’t get working, was to measure the actual mm length used by each section (including any images) by rendering each one individually to a single page, and then try and sort them so that they minimised gaps. The measuring I could do, but the constraint satisfaction required to order them didn’t work out. Reading up, its considered to be an incredibly hard problem even for a dozen items, never mind the 3-400 in a COYA
Something I thought about are ways to try to do heuristics for reasonable length of jumps. It is not fun in a long book to have to jump from page 3 to page 200, then back to page 4. Ideally jumps are not within the same page, but not many pages away. At the same time if the story keeps going back and forth in a limited range of pages you can accidentally see many other branches around the story where you currently are. So probably the story should drift a bit, maybe tend to move one or a few pages forward, then start to go back from when it gets close to the end of the book. I do not know for sure.
There is a book about writing your own solo adventures for Tunnels & Trolls, containing an internal document by the publisher originally written around 1980. It contains some method for assigning order to sections in a somewhat structured way. I have not studied it enough to see if it would be worth trying to steal some ideas from it. Otherwise try to think of something else. Maybe an organization that is not so random is better than just a random shuffle. But if trying to also consider page-breaks and the length of sections that will definitely complicate things. Maybe the best way would be to implement multiple possible orders. Or to only support the most basic ways and leave advanced optimizations to wrapper scripts (or manual editing).
The method I was thinking of is described in How to Write a Solo (Flying Buffalo, 2019). It is a collection of guidelines of how to write solo adventures (i.e. gamebooks). Section numbering is covered in a document titled “Solo Design Guidelines Supplement No. 3” from 1986. There is a blank Solo Numbering Work Sheet, and a process with 7 rules for how to fill it in to end up with shuffled sections in a reasonable order. It is a good thing with those old pre-computers instructions that they have to be so specific. If it was a computer doing it, like with Pangamebook, the method often ends up more ad-hoc.
Rule number 3 is the “absolute rule” that “A paragraph that goes to or comes from another paragraph should be no closer than 15 paragraph numbers apart”. That is exactly the kind of thing I have thinking of putting in my script (but probably make it configurable?).
Basically the method in that book is to add sections in order in a way that makes the story mostly jump forward in increments of ~15. So if you have three choices in section N there will be one leading approximately N+15, one to N+30 and one to N+45. But it wraps around modulo the number of paragraphs in the book, so one or more of those could end up in the beginning of the book. It looks like a method that would be simple to implement and much better than my current shuffle. Worth considering.
I find that this kind of constraint works well with a technique that I think of as “relaxation” – generate some starting state (often just random) and then loop through pushing the related posts around so they satisfy the constraint. This will often cause it to violate some other constraint, so try again until they’re all good or you reach some max number of attempts. They usually converge pretty quickly, fail only when the solution is getting fairly close to impossible (like there aren’t enough paragraphs to meet the constraints), and are easy to code…
Sort of like Newton’s method or other iterative methods for solving calculus problems: make the solution a little better each time until it’s close enough. Like those methods, it works best for things with “smooth” problem spaces. So like here, shifting one paragraph over is only ever going to make other paragraphs one closer together. But with things like “minimise the gaps” you might have a situation where fixing one gap pushes one line over onto the next page in a dozen places. So that solution space is highly “spiky” and is a much harder problem…
Both could be used. Instead of starting from a random shuffle a simple algorithm trying to skip shead fixed distances could be used. That could optionally be post-processed to nudge sections around to fix issues.
But I still do not think I will try to tackle page-breaks. Too output-format specific.
I also remembered that the current implementation allows for pinned numbers on sections to split the story into shorter ranges that are individually shuffled. That causes some extra complications, but I can think of a reason to keep it around at least as an option.
I think that in particular is a great idea, and I’ve been musing how to add it to Gordian.
Right now Gordian takes all the fixed numbered sections out in a first pass and pre-allocates their numbers, then shuffles the rest and assigns the available remaining numbers. It can handle things that must go last or first, but doesn’t have a way to split the shuffled numbers into a before or after.
What do you do the number of sections before a fixed one is less than the number given to the fixed section? Are numbers left unused?
A little trick I use is to have the paragraph length to be variable. Either put in some extra lines, or add illustration to pad the space. That way, you don’t have to calculate things to a line just to fill the page neatly.
It still takes lots of manual juggling to do that, adding illustrations, taking them away. I usually make three filler/cut images of different heights, 1cm, 1.5cm, and 3cm and use those to pad out pages that have too much white space.
I ended up implementing the method, I think, almost exactly like in that old document. Did not plan to, but after thinking a bit I realized how much simpler (and also easier) it makes things. Plus as an author you can tweak the output quite easily by moving around sections in the input document and maybe be able to understand what is going on since the algorithm is so simple and predictable.
Setting gamebook-gap in metadata can be used to control how far the distance will be (if possible) between sections. Default is 23 (subject to change). Unless there are any sections that have fixed numbers in the input document they will be numbered in order as 1, 24, 57, 82 … and when they hit the maximum number wrap around to 2, 25, 58, … and so on.
There is no clever logic looking at links between sections, or any magic to try to optimize things, but from testing with three (small) books I like the results. It’s on the author to organize the document so that sections that are related are ideally close together (which will mean they end up NOT close together in the output).
I realized that looking at links and trying to optimize the book based on those is not necessarily correct anyway. There may be sections that are far from each other in the link-graph of the book, but that the author still do not want to show up too close because of spoilers. With this simple method of ordering the sections it is at least theoretically possible to manually move sections around to ensure that without having to resort to hardcoding any numbers.
Want to test it a bit more and work on the documentation (that was updated, but I am not happy with it) before pushing to GitHub (from my private fossil repo).
Since I wanted some more test-data I asked ChatGPT to generate gamebooks for me and it was scary how good it is (and this is the old free ChatGPT). OK the stories are not very interesting as stories, but they branch properly and can be navigated and there is a beginning and sort of end and various little things to do. I think I will add a few as official example books in the GitHub repo (but I will make sure to mention they are generated and not meant to make much sense).
And since the style of Markdown it spits out is varied and not always quite written the way I do, I already found and fixed two bugs thanks to using this generated test-data. Definitely going to have it spit out many more stories to fill up my collection of test-gamebooks that I use for regression-testing.
# start_
You find yourself standing at a crossroads in a dense forest. You can't
remember how you got here, but you know you must make a choice.
To go deeper into the forest, turn to [deep_forest].
To head back the way you came, turn to [return_home].
# deep_forest
You venture deeper into the forest. The path ahead is shrouded
in darkness, and the sounds of unknown creatures echo through
the trees.
To explore the dark path, turn to [dark_path].
To turn back and return to the crossroads, turn to [return_crossroads].
It seems to work reasonably well. No obvious bugs anyway. Pushed it to GitHub:
New method of sorting sections plus various bugfixes. Now tested with bigger gamebooks, with the biggest being a bit over 100 sections. No full 400-section one yet, and nothing like some modern gamebooks with 1000+ sections, but I do not think that would be a problem.
Hi @pelle, this tool looks really nice. I have no immediate project to use it, but just wanted to pop in to say it’s great to see traditional CYOA book formats supported.
There was a discussion earlier in this thread about page-breaks. I just pushed a new version of this script to my GitHub that has a setting for adding recommended or forced page-breaks. It is not perfect, but it seems quite good. It only works for LaTeX output (which is what is usually used for generating PDFs).
I think there are some similar workarounds that could be applied to other output formats, but I did not look too much into that. I think PDF output is the most important one where page-breaks matter. EPUB output will always use one page for each section anyway. HTML and text-formats just have one long page for the entire gamebook.
This of course is not as good as what was discussed earlier here, with trying to order sections in a way to fit the pages better. That is still not likely to happen.