I’m working on an input parser for a javascript game, and looking at various approaches.
In 2020 I wondered what “giants shoulders” there are to stand on from NLP to compilers
I’m familiar with the NLP approach but wanted to ask what other options people have used, and thought I’d share some other ideas I’ve come across so far.
RegEx parsers
The basic crude approach is to use regex and matches. This actually gets quite a long way! But it’s a pain to write. An excerpt looks like this with named captures:
route(/^(?<action>take|get) (?<item>.*)$/i, Actions.take),
route(/^(?<action>drop) (?<item>.*)$/i, Actions.give),
which matches on take cake
This will get a lot more ugly with sentences with compound clauses:
route(/^(?<action>use) (?<item>.*) on (?<item>.*) $/i, Actions.give),
match: use key on door
Lots of code for the basics eh.
RiveScript is an example chatbot script language that has a “simple regex” format that allows you to do things like this and also deals with regex captures
+ what is your (home|office|cell) number
- You can reach me at: 1 (800) 555-1234.
+ i am # years old
- A lot of people are <star> years old.
But there must be a better way than asking creative writers to deal with this stuff amirite?
Some type of spec languages to say what works where?
DSLs
I’ll just mention “domain specific languages” here, as a way for users to talk to computers.
Usually this is where you define a specific way to communicate and the human has to learn that language to talk to the computer.
This actually seems very similar to how text adventures walk go west or use key on chest are more computer-friendly than “natural” language.
I’ve written some DSLs using ruby as its a language where code basically reads almost like prose. method_missing ftw!
Smokestack.define do
factory User do
name "Gabe BW"
pet_name "Toto"
end
end
It’s great when you write them but can be a nightmare using someone else’s, eg like AppleScript
Grammar based parsers
Given a fairly structured language.
There is a whole field of CS for more structured computer languages and “grammar definitions” and parsers for them.
ISHML
@bikibird has created something really interesting in ISHMaeL

if you haven’t I suggest you read this thread. You heard it here first folks!
example:
| input: | take the glass slipper |
|---|---|
| verb | take / take |
| adj | glass / slipper |
| noun | slipper / slipper |
I tried integrating into my nodeJS engine.
PegJS
PegJS is pretty well known in this domain.
I am still getting to grips with things like defining your lexicon and grammars but it was a very approachable on-ramp.
But I’m not quite sure how to define an adventure game grammar for PEG.
I couldn’t find much information on this topic. Here’s a grammar for JS itself.
Anyone have an idea?
other compiler parsers
Earley parsers are another approach here.
which @JoshGrams is an expert on.
NLP approach
Separately I’ve looked into NLP parsers such as spaCy which give quite a good breakdown of parts of speech.
The results seems really good and because its based on existing training data, you don’t need to define your own grammar.
The output is less customizable for the specific domain of intfic
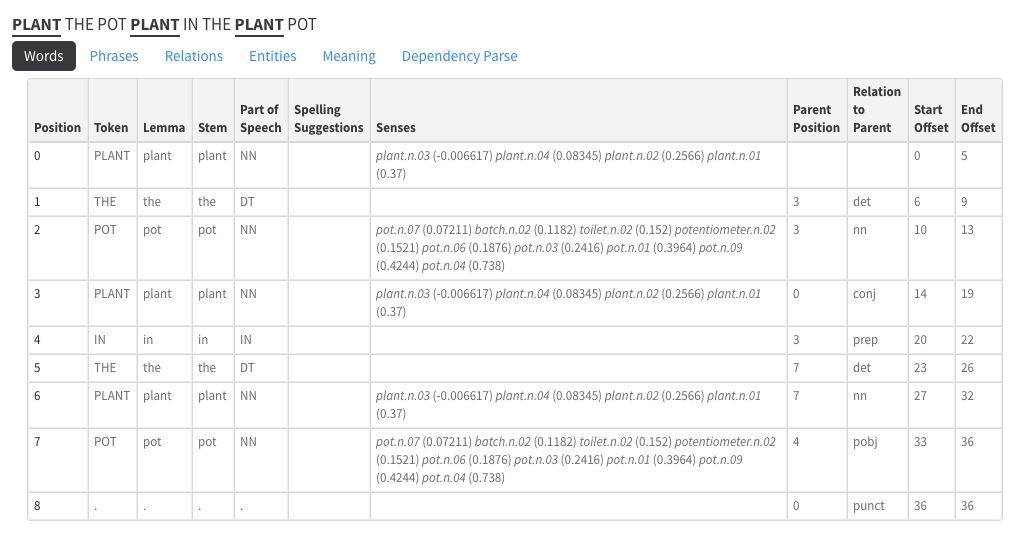
parts of speech (POS tagging) is an NLP way to figure out what are nouns/verbs etc. in a sentence. basically tokens per word.
Then dependency parsing will show you the sentence breakdown ie the relations between those tokens
Spacy even has a displacy for visualizing
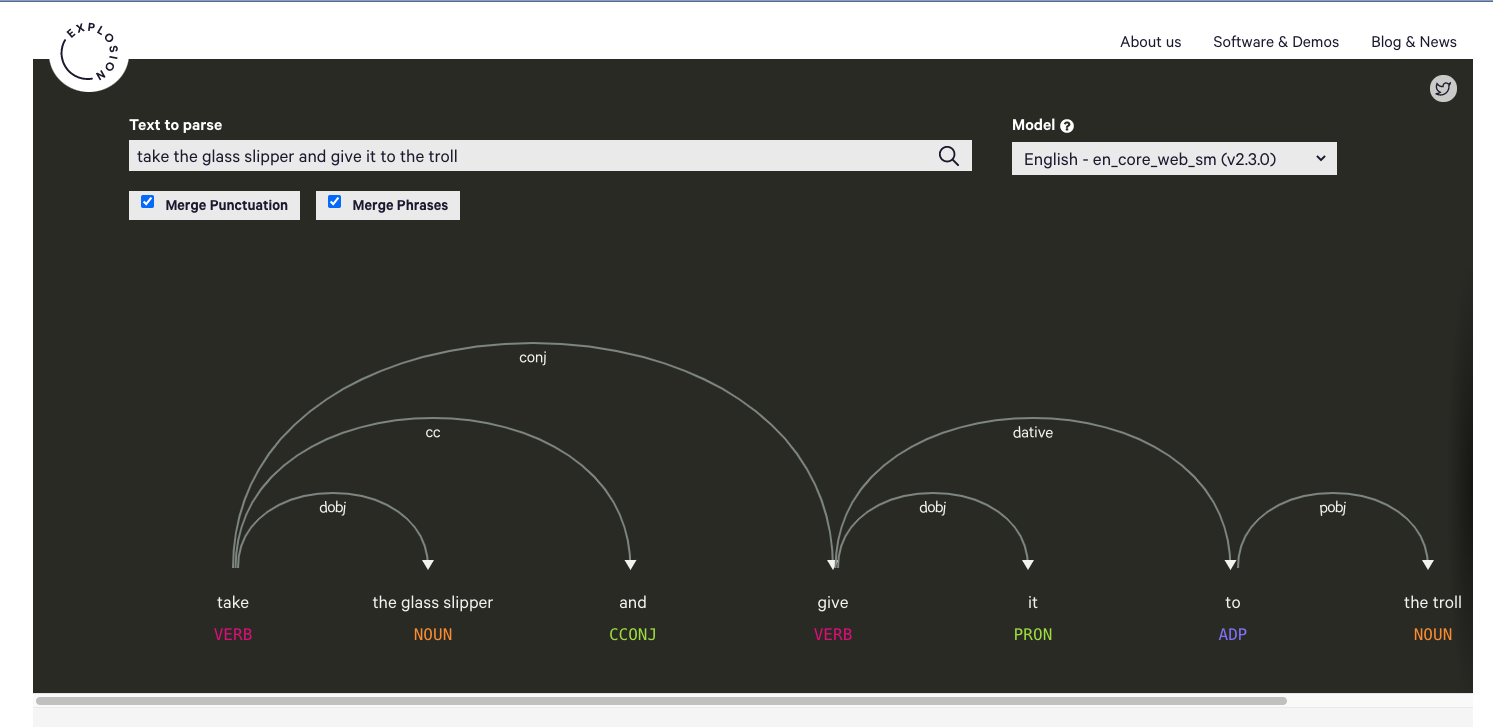
And there are API/services like TextRazor for those who don’t want to run it all locally
LD A, (de)
In researching I found this great video about writing a parser from … back in the day. Man it used to be so much harder! The more things change…

can you remember jump tables?

What are you doing?
So those are some of the approaches I’ve found today.
It would be great to hear what other approaches people are taking, and specifically any details on better ways to use grammars like PEG
Sorry for the long post.