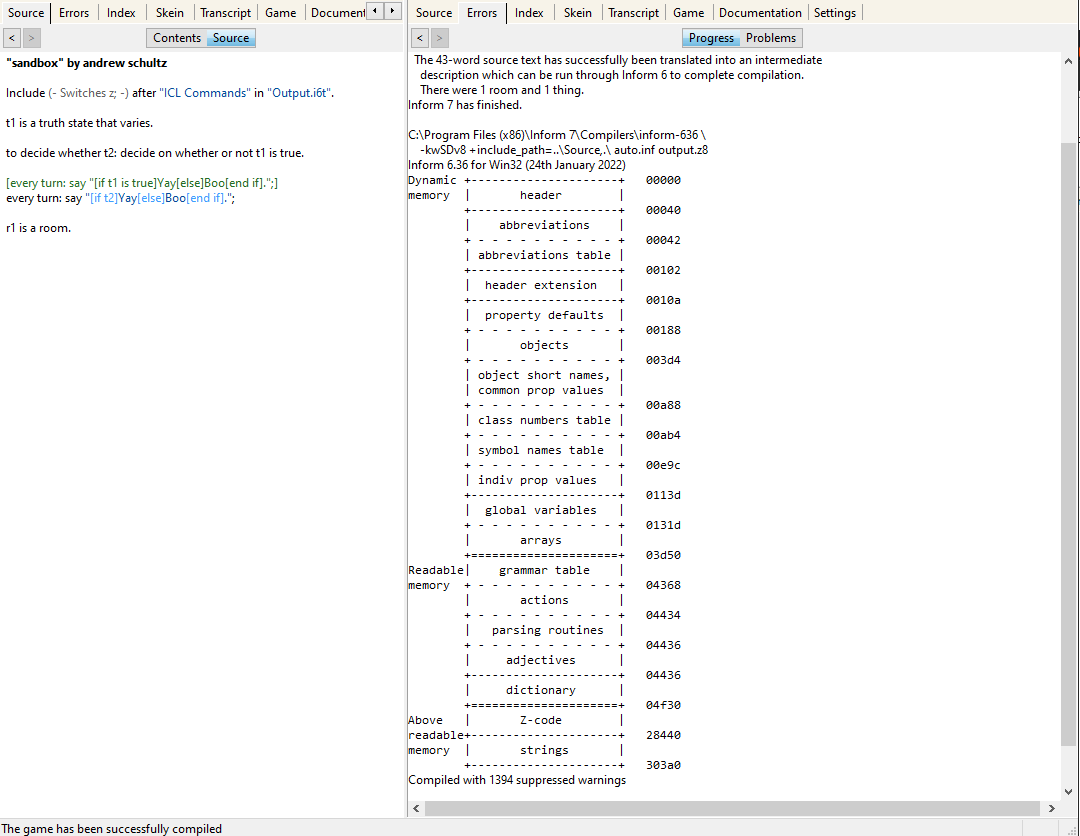
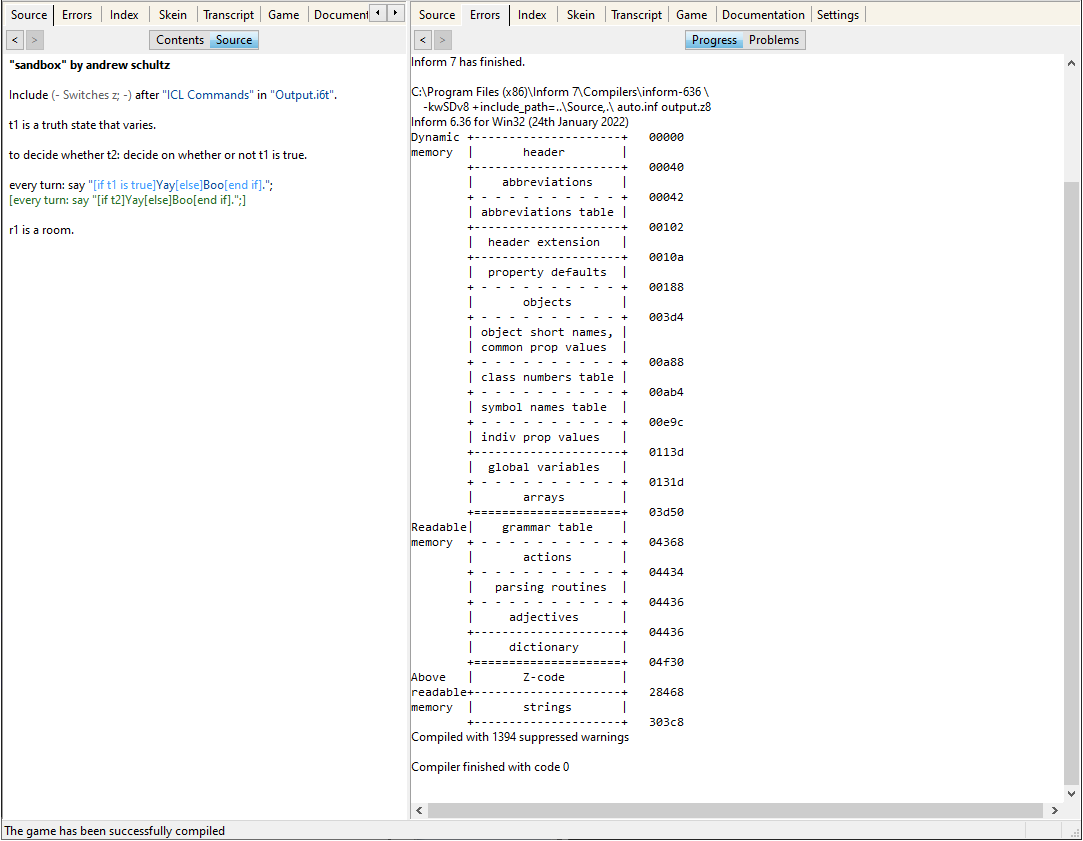
Include (- Switches z; -) after "ICL Commands" in "Output.i6t".
Helps me track how much z-code memory is used when my I7 code is compiled and interpreted.
I’m trying to keep my latest project in Z8 format if at all possible, so I thought I’d use truth states a lot.
So for instance I used
if score-act-1 is true, say "Okay."
Where score-act-1 is set to true when an item (called the hat) on-stage.
But I also tried
if hat is not off-stage, say "Okay."
I would expect the second command to take more memory than the first, but the first takes more. What can account for this? I have about 100 truth states, but I don’t think this affects things.
The i6 interpreted code is as follows.
Truth state comparison: if (~~((((((Global_Vars-->84) && true) == (1 && true)))))) jump L_Say806;
Check if item is off-stage: if (~~((((~~(((~~Adj_9_t1_v9(I132_hat))))))))) jump L_Say806;
This may be semantic, and of course I can get rid of the globals I created if I really want to make sure the project is at Z8 size, but I’m baffled what’s going on here. My intuition says comparing truth states should take less space, but the reverse seems true, and I am clueless why.
The location of every object is already stored, so when you check if something is off-stage, it’s not using any extra memory. But when you make a new global variable that has to take 2 bytes. Even though it’s a truth state, I don’t think Inform will combine truth states together, so each one gets its own two bytes of storage.
If you store the value explicitly, then you can look it up with a single memory access (very fast). But you need to dedicate some space to storing it.
If you compute the value whenever you need it, you don’t have to store anything extra (very small). But you need to go through the whole process of computing it every time.
In this case, the actual computation is pretty fast; the “is off-stage” routine Adj_9_t1_v9 just looks at the object’s parent in the world model to see if it’s nothing. And storing the value uses up one more word of precious, valuable addressable memory, which is the most significant (and most insurmountable) limit of the Z-machine. So I’d say optimize for space rather than time here.
As a side note, one good way to optimize for space rather than time is to implement constant adjectives (i.e. ones that don’t change very much or at all) as definitions rather than properties.
This creates a new routine, using only packed memory, optimizing for space rather than time:
Definition: a thing is metal:
if it is the triangle, yes;
if it is the square, yes;
if it is the robot, yes;
no.
But this creates a new property, using up precious addressable memory, optimizing for time rather than space:
A thing can be either metal or nonmetal.
A thing is usually nonmetal.
The triangle is metal.
The difference isn’t huge, but if you’re trying to fit an I7 program into the Z-machine you might need to use any slight advantage you can get.
This is a hazard of trying to use boolean logic in I6. if (x == y) may evaluate wrong if a non-boolean value has snuck into x or y. That is, one of those values is 2 and the other is 1, they won’t compare right even though they both represent true.
By writing if ((x && true) == (y && true)), you squash both sides to 0-or-1 and then can compare them safely with ==.
I’m not recommending that I6 authors start doing this! It’s really uncommon to write (x == y) when you’re thinking about booleans. You certainly wouldn’t write (x == true). A normal person would just write if (x) and avoid the whole problem.
But the I7 compiler is just generating code from a tree of expressions. It’s easier for it to apply this safety-pattern everywhere than to simplify the output on the fly.
“If (truth state)” costs 40 more bytes than “if (definition)”, with all other things being equal during compiling, (303c8 vs 303a0) which is a nudge to me to use definitions more (a good coding practice,) but I’d have thought it’d be the other way around. And the 2 bytes for a boolean don’t account for the difference on their own.
Is there a reason for this? As-is, I’ll be glad to roll with it, but it looks like the sort of question that might give me a lightbulb moment when answered.
Ah, that difference is just in the compiled code itself. And there’s generally plenty of space for that.
The main limit to worry about is the line between “readable memory” and “above readable memory”, which is 0x04f30 for both of your screenshots. Above that is just the actual compiled routines, and running out of space for those is uncommon—generally you’ll run out of readable memory first.
Is it compiling with $OMIT_UNUSED_ROUTINES=1? I wouldn’t be surprised if it’s bigger only because it’s also including code for the definition even though it’s never used.
No, it’s not, but thank you VERY much for letting me know about OMIT_UNUSED_ROUTINES! I never knew about it, and it just saved me x5000 of z-machine space. That makes asking this question very, very worth it for me and potentially others! I always wondered if something like this were available.
Here are some data points I have from a 6g95 build
It looks like the t1 rule adds a different amount of bytes depending on what is already there.
From nothing, it adds 0x90. With the definition there, it adds 0x90. With t2 and the definition already there, it adds only 68.
The t2 rule adds a different amount of bytes, too. From t1 + definition, it adds x40 bytes. From definition, it adds 0x68.
So overall, without OMIT_USED_ROUTINES, the t2 every-turn rule adds fewer bytes to the z-machine memory.
Since you’ve alerted me to OMIT_UNUSED_ROUTINES, this has rapidly veered into the realm of intellectual curiosity that won’t keep me up at night. Because I asked this question while looking for ways to save bytes without nitpicking, and boy howdy did you show me a good one! (A bit of searching shows it’s been around for 8 years, in fact. Wow.)
The I7 v10 compiler automatically includes !% $OMIT_UNUSED_ROUTINES=1; in its i6 output. (And it is bundled with I6 6.41; in I6 6.40 Zarf implemented dead code removal, another space optimization.)
Thanks for the details! I’d been using 6.36, and I was happy to have the compiler speedup and not to have to track USE MAX_ syntax.
So this is another reason for people to upgrade their compiler even if they don’t want to use the IDE and to pay full attention! I know there’s been a team that has made all kinds of upgrades over the past year or two, and that sort of thing’s helped make my programming time a lot more efficient.
The size of “readable memory” is tied to a fundamental limit of the Z-machine: how big a number can be. Every byte of readable memory has to be addressable, meaning there needs to be a unique number that points to it, which you can use to read and write it. That’s why it’s never gotten significantly bigger across different Z-machine versions.
In “non-readable memory”, though, we don’t need an address for every byte: we need an address for every routine and every string, since the only things you can do with non-readable memory is call it or print it. So later versions of the Z-machine applied a larger and larger scaling factor to non-readable memory. Z8 uses a factor of 8, meaning there’s one address for every eight bytes, so you can have approximately eight times as much non-readable memory as readable memory.
In theory, Z9 could have a factor of 16, giving you twice as much space there again. But as far as I know nobody’s done this, because a factor of 8 is plenty: you’ll run out of readable memory (tables, objects, properties, variables) first, and the only easy (“easy”) way to break that limit is to make the size of a number bigger. Which changes absolutely everything about the Z-machine.
If you make that change, the limit on readable memory increases from 65,535 bytes to 4,294,967,295 bytes, and you can actually scale that by an additional factor of four if you decide to use word addresses instead of byte addresses. Which gives a limit so high nobody will ever hit it in the foreseeable future.
currently the largest IF is archeological fiction, a .gblorb of 762,222,472 bytes (727 Mbytes), but I can’t say how many is the actual story file and how many are the audiovisual resources.
the largest .ulx file I know is Shapes, a 1,253,632 bytes (1,2 Mbyte) glulx story file.
so, I think that in the foreseeable future, the (storage) memory issue lies in the bundling of story and resource files.
I’m not familiar with either of those games, but I would be willing to bet the vast majority of that blorb is sounds and graphics. The actual bytecode is pretty compact, and the text is Huffman coded (and also not huge to begin with). And thankfully images and sound aren’t subject to the same restrictions because they’re never loaded into the VM’s memory, only the interpreter’s.
In theory we could eventually make a new VM with 64-bit words, but I don’t know if that will ever be necessary, unless there’s a fundamental change to what these systems are used for. 232 bytes can support a truly incredible amount of variables, tables, and objects.
As for largest IF, there was an ADRIFT game that hit the 2GB limit for blorb. (At least, ADRIFT blorbs at the time used signed ints.) But that was predominantly media.
I cut away a huge chunk of hinting code that was no longer necessary. It had a tone of “if sco-xyz-abc is true, decide 17” style text.I mean about 50 lines or so. The memory used didn’t drop much. A lot of these if statements, if not all, were used elsewhere.
So this was empirical proof of (what I think) the more high-level stuff people were talking about here. There’s a big hit the first time you compare a truth state but nothing the second.