Or more generally that our approach to both classes of problem is just a bunch of recursive substitutions. This is assuming that when we’re talking about procgen stuff we’re only interested in computable (partial) functions.
If anyone is having trouble getting a feel for what this means, it’s more or less the same thing you were taught in high school algebra: if you start out with a big ugly algebraic expression and apply a bunch of substitutions and simplifications and eventually end up with x = 4, then (assuming you made no mistakes), that means that the big ugly expression was just an elaborate way of writing x = 4.
With procgen stuff, you’re basically doing the reverse. You’re starting out with something like x = 4, and you’re recursively inverting algebraic simplifications to produce a big ugly expression.
Anyway, I don’t know of a reference that walks through the specific equivalence we’re talking about here, much less one that would work as an introductory text. E.g., the Dragon Book, one of the seminal references on compiler design, uses graphs to illustrate state transitions in lexical analysis, but a) not in a way intended to specifically illustrate the equivalence of the grammatical and graph representations, and b) the Dragon Book is a pretty crunchy read even if you’re really invested in learning compiler design, and is waaaaaay overkill as a general introduction to formal grammars.
I’m sure I’ve seen the subject discussed in e.g. gamedev presentations and so on, but I can’t think of a specific example at the moment.
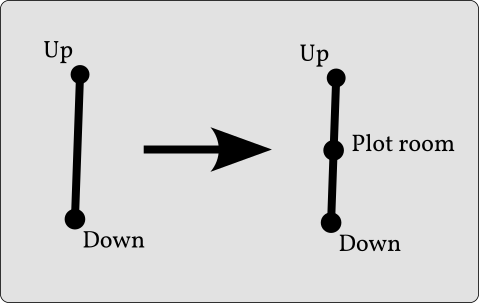
In terms of the “dungeon” example:
In the terms I was using, the productions correspond to graph vertices, which I was imagining as rooms. The hallways are the edges, which in the simple grammar are implicit.
That’s not necessarily true (that is, I’m not trying to advocate for this specific kind of system). I was just trying to sketch out a specific use case. That is, older roguelike procgen map generators frequently used trial and error to dig maps. The point I was making is that you can avoid this by always having a map that’s in a consistent, “solvable” state. So instead of randomly placing rooms and then randomly digging hallways and hoping everything ends up connected, you can use a graph where the rooms are vertices and the hallways are the edges—if you start out with a graph where you know you can reach each vertex from every other vertex (because there are only two and a single edge) and you expand the graph only by replacing edges with subgraphs that are themselves traversible, then you know that the final graph will be “solvable” by the player.
In this case I’d start out with something like (I hope this is accessible):
upstair - downstair
…and then say one of your building blocks (“known good” units of stuff you can use in your substitutions) is a pair of rooms connected to each other. We’ll call each set of rooms “foo” and “bar” and we’ll number them to keep track of the order we added them in. So after one substitution we’d have…
upstair - foo0 - bar0 - downstair
…and after another we might have…
upstair - foo0 - foo1 - bar1 - bar0 - downstair
…or, alternately…
upstair - foo0 - bar0 - foo1 - bar1 - downstair
…or…
upstair - foo1 - bar1 - foo0 - bar0 - downstair
In our simple grammar that would be something like:
- LEVEL: ‘upstair’ FOOBAR ‘downstair’
- FOOBAR: [ FOOBAR ‘foo’ FOOBAR ‘bar’ FOOBAR | '' ]
…making no provision for bookkeeping like our numbering system.
That is, our level always consists of an upstair and downstair connected by some stuff, where the stuff is recursively defined.
In this case all of the hallways are implicit. We could make them explicit via something like replacing the empty string in the FOOBAR definition with ‘hallway’, or we could (if we didn’t want to build simple linear “dungeons”) use some more elaborate syntax to accommodate rooms with more than two connections.
But if we wanted to do that, we’d probably be better off just using a graph, because that kind of information is generally easier to handle that way.
The opposite is generally true when you don’t care about the relationship between the individual parts or the relationships are implicitly obvious/handled by something else. E.g., in the original example of creating procgen dinosaurs (in IF), then you probably don’t care that the head is connected to the body and the body is connected to the legs but the head isn’t connected directly to the legs. So a grammar that doesn’t attempt to enunciate the relationship between the parts is probably all you need.