thanks for the reply!
I meant in terms of the top-level ## items in that example demo script.
Which I think are called “pages” right?
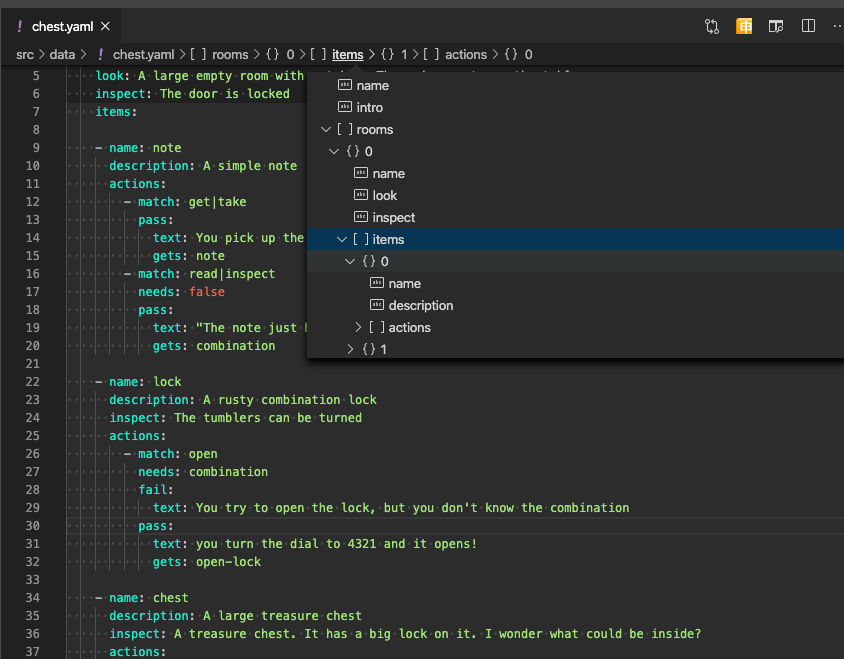
I’m confused because some pages are named after people erin and others inventory or remote. Perhaps those are just like names for “scenes” in a movie, maybe “talk to Erin”
Is that just a visual separator or is there any functional importance to it?
Since you have labels also which are used for jumping around, I think.
>> label //jump to a label
The script resumes here after the jump.
Clicking [:new_page @: here:] will jump to a new page.
<< END //the script halts here to wait for input
= label
A benefit is you could use a markdown renderer and provide a visual outline to authors, as it’s an H2 symbol.
It reminds me a bit of RASA’s NLU story format, which is a kind of weird markdown hybrid. This is really just a format for training texts for an NLU (natural language understanding) engine, so more like a parser in IF parlance.
So that would mean that ++ is two steps indented?
It seems like a neat hack to make parsing easier, but from a UX - it also means people have to be very specific in their use of token counts, whereas the indent does NOT actually matter. I’m not sure that is intuitive…? But it’s good for copy and paste, sharing stories, unlike python’s whitespace rules…
maybe if you were flat formatting…
+ topic
++ subtopic
+++ subsub
then token count matches the indents…
I do really like the “outliner” format for story authoring though, how you can nest blocks, and then continue or fall “up” the conversation tree when a topic is exhausted. I believe Minsky wrote about that topic in Society of Mind but I can’t find the reference now.
The very first version of the pullstring IDE had a nice “outliner” style where all the indentation was managed for you, but “significant”.
Personally I’m trying to go far with a structured YAML format, so I don’t have to write my own parser for authored scripts.
But that approach does make it a little obtuse to author logic like conditionals. I’ve considered things like the mongoDB query syntax, where it’s purely expressed as data eg:
var query2 = {
$and:[
{userName: "bob"},
{animal: {$in: ['beefalo', 'deerclops'] } }
]}
really ugly as JSON or YAML but the benefit is you can provide a visual editor as the syntax is very defined. And the parser is also available.
anyway back to work
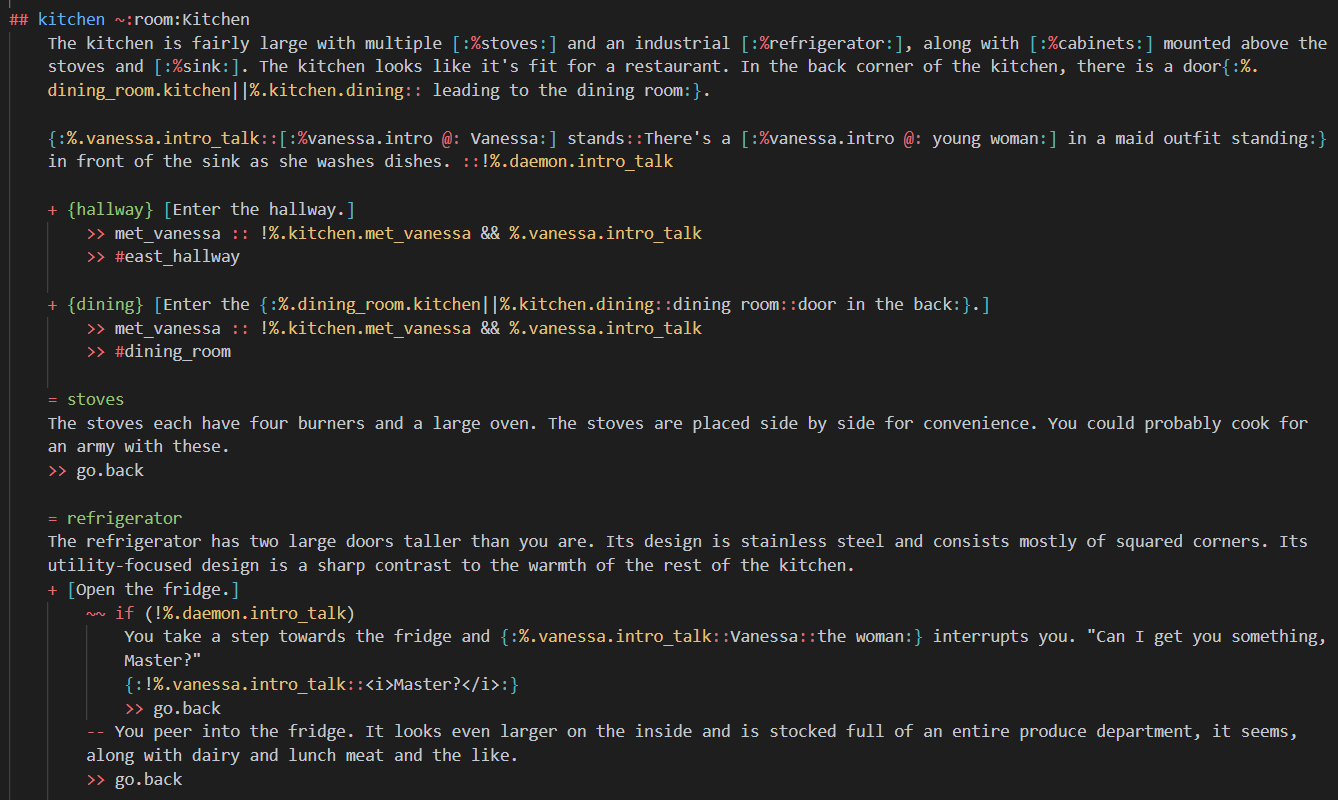



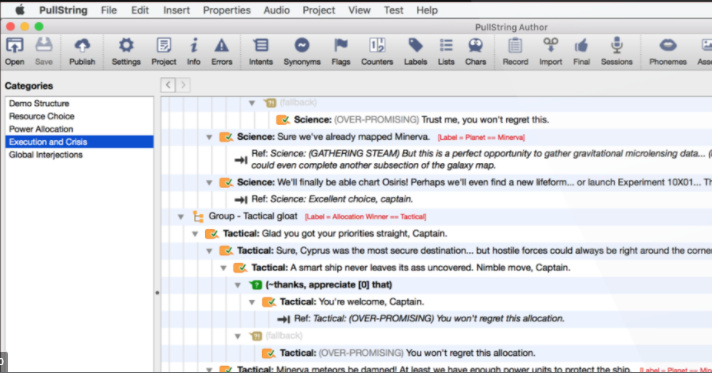
 I’ve never seen that before, but it does look visually similar to my syntax on the surface, even though it doesn’t function even remotely the same. It’s funny how they chose
I’ve never seen that before, but it does look visually similar to my syntax on the surface, even though it doesn’t function even remotely the same. It’s funny how they chose