…so I recently got an email out of the blue from someone asking for help with my game, Changes. I mentioned the (rather inadequate) built-in help, and they said that if they tried it, the game crashed; turns out that they’re blind, and playing the game on a BrailleNote Apex’s built-in Z-machine interpreter.
Firstly, the BrailleNote has a built-in Z-machine interpreter! How awesome is that?
Secondly, it seems to be based on jzip 2.10 (search for ‘text adventure’ in edvisionservices.org/Manuals/Bra … 0Guide.pdf) and I managed to duplicate the crash with the version of jzip in Debian.
According the TXD, that address isn’t an instruction; it’s a data block, so it sounds like jzip has jumped into nowhere. This is almost certainly an interpreter bug; the game runs fine everywhere else. Now, there’s no chance whatsoever that my correspondent can upgrade their interpreter. Is there anything I can do? Has anyone seen this issue before?
Changes is an Inform 7 game, written in whatever the current version was in 2012. It uses 0xfff8 bytes of low memory, so it only just fits in Z8, which means making it bigger will be hard…
TXD might not be completely reliable here, as the Z-Machine memory layout doesn’t have a distinction between code and data. However, running the game in Frotz doesn’t show that PC value being reached.
If I were tracking this down, I’d start by hacking jzip to write the PC to a file as each instruction is executed, then look at the last few instructions to see if anything obvious was going wrong. Failing that, I’d put the same hack into Frotz and see where the two streams of PC values differed (though you’ll have to watch out for things like the random number generator). However, it’s hard to imagine that it will prove to be anything that you can work around in the game.
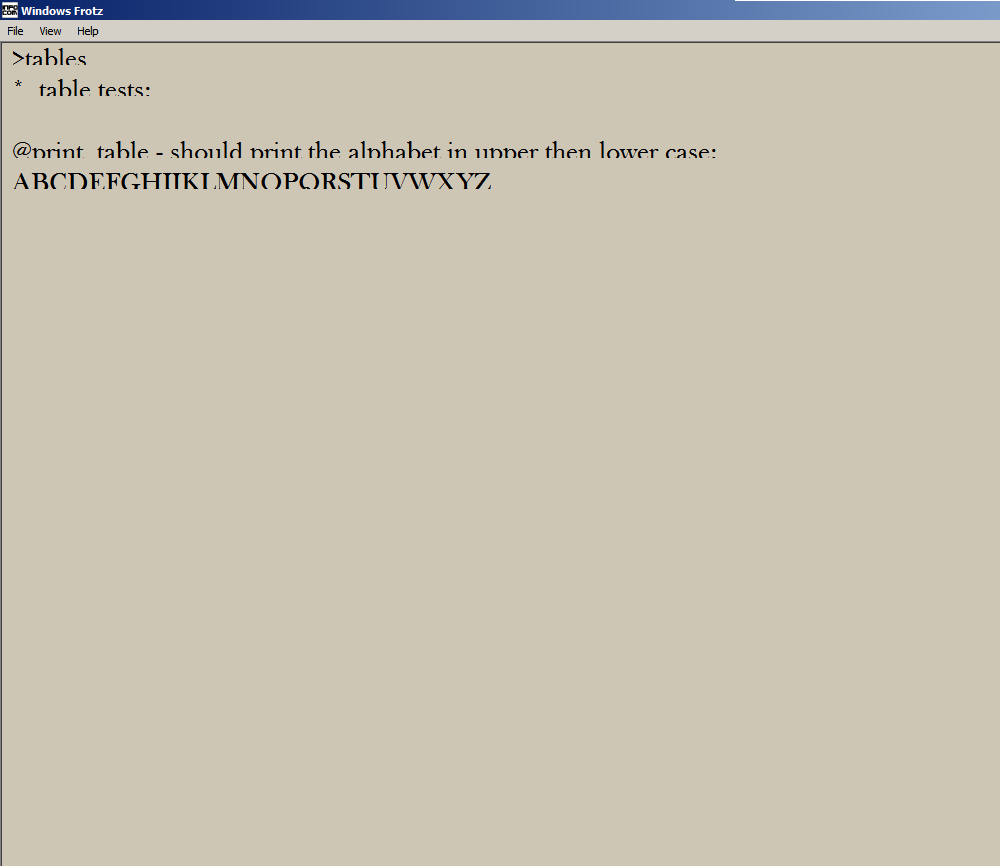
Sorry to barge in and go a bit off-topic - I took a look at Praxis, because I’m a curious person even when I know I won’t understand most of what I’m going to see, and it seems that in Windows Frotz (1.18 at least) testing “tables” screws up the output; I get cropped characters, only the top half of the alphabet is visible until I type “look” again. Should I be worried? Is it normal?
Sure. Interestingly, I tried again. This time I tested “tables” as my first command - and it displayed perfectly. Then I tried again, convinced I’d made a fool of myself, and the second time… see for yourself.
This is repeatable. First time, first command “tables”, ok. Subsequently… it gets worse and worse, like it’s getting offset by a pixel, until no characters are visible at all.
I have now committed a fix for this to my GitHub repository. I won’t bother making a new version of Windows Frotz for this, as really the behaviour of the @print_table opcode was never properly specified in the lower window, at least not until the latest Specification 1.2 attempts.
I just saw this. I’ve been really not involved in the if community for a long time… however I fired up Jzip, duplicated, and fixed this bug yesterday. I’ll try to get it into my sourceforge repo this week.
The issues: I never implemented print_unicode or check_unicode extended opcodes from standard 1.0 yet still claimed 1.0 compliance (which my sourceforge page mentions). I went ahead and implemented them yesterday over lunch. “Changes” uses the copyright char with print_unicode as well as unicode 0x2022 “bullet” in the help for “license” and “credits”. This caused Jzip to crash as the opcode was unimplemented.
I have no idea if anyone monitors the Jzip source repo for updates, so getting the fix downstream will most likely take awhile. I do know that due to my ultra-permissive license that it is used in a few reader apps for the blind.
Hah! I’d completely forgotten about this. Not surprising, really.
Anyway, thanks very much! It sounds like the simple fix at my end is to simply remove the non-ASCII characters. For that I would need to be able to recompile Changes, which I don’t think I can any more due to logic drift in the Inform toolchain (it’s I7 compiled to Z-machine using literally the largest game file possible).
Maybe I should take some time to overhaul Changes and make it better; it’s way too hard, and the endgame is decidedly phoned in, which is a shame as I’m rather proud of the way plot and theme came together in that and I’m not sure that many people actually finished it…
I wouldn’t change Changes (Ch-ch-ch-ch-changes! ok that’s out of my system). The crash is because my interpreter lied about spec 1.0 compliance. So this is all on me.
On the plus side, it was kinda nice working on such a small simple codebase. My day job is as an architect on a 17.5 million line large business software product wrangling Java, C, and C++…
Would you be able to recompile it to z-code using the older versions of Inform that are available on the inform 7 website? Though if you used extensions it might not be easy to find the right versions.
John, I recently needed a linux/windows console Z-machine interpreter and jzip seemed like the best choice. In the process I made a few changes, which I maintain in https://github.com/borg323/jzip. If you see anything you like, I can clean it up for inclusion in your repository.
@borg323 - I did a cursory diff of the code in Beyond Compare…
Good stuff here, more undo flexibility, and other patches.
I’ve taken the source dump from your github and built it, and have made a number of mods and patches, partly to allow dumbio to output UTF-8, others are for some issues I’ve fixed over the years, such as Jzip didn’t work with newer versions of zlib (for use with compressed story files), it had a macOS crash on termination, and general cleanup I made over the years with analyzers such as valgrind, Fortify, and MSVC’s analysis tooling. Dumbio with a new compile flag -DDUMBIO_UTF8 now works on Linux (and on Windows after running chcp 65001)
I’ve still not verified the zlib works, or after my changes, winio & cursesio (with ncursesw). Will check those and also some alternate UNIXes (Solaris, HPUX, AIX).
I pushed two more changes that I had locally, a bug fix and basic zblorb support. Regarding zlib, I have already merged some changes from the debian distribution and they seem to work.
BTW, it seems sourceforge has decommissioned cvs - are you planning to move to another system?
@jholder, regarding the use of ncursesw, I was trying to code for the X/Open Curses specification (using http://pubs.opengroup.org/onlinepubs/7908799/cursesix.html) hoping for more portability with Unicode, but ncursesw was the only compatible version I found on my linux system. Seems I did mix-up the use of WA_ and A_ attributes, which may cause portability issues but should be easy to fix. Other than that, I tried to add the few wide char calls in separate code paths, with portability to other curses versions in mind.
Good point about sourceforge CVS being dead. I completed testing on my updates for dumbio with your base, which required me to modify the signatures of a number of routines to ensure unsigned values made it through to the IO layer.
I then tested windows with conio and dumbio, linux with cursesio, unixio, and dumbio, and everything is working across these platforms. I’ve not yet had time to give the other unixes a go, but if unixio is still working there too, that would be acceptable.
It might be easier just to send you the updates for now to see what you think. Is there a way to DM or exchange email without posting it on the board?

 [/rant]
[/rant]