Probably one for @zarf. I actually noticed this some months ago but it didn’t really bother me until I started developing Ghosts of Blackwood Manor.
It seems that the line error reference calculation in the compiler is wrong. So when it notices an error, the integer output of the line reference is actually expected number x2 (sometimes rounded, so one off). Looks like it could be a problem with 32-bit / 64-bit integer conversion but it might be something else as well. Here is an example.
As you can see here, the compiler claims an error found in line 1517.
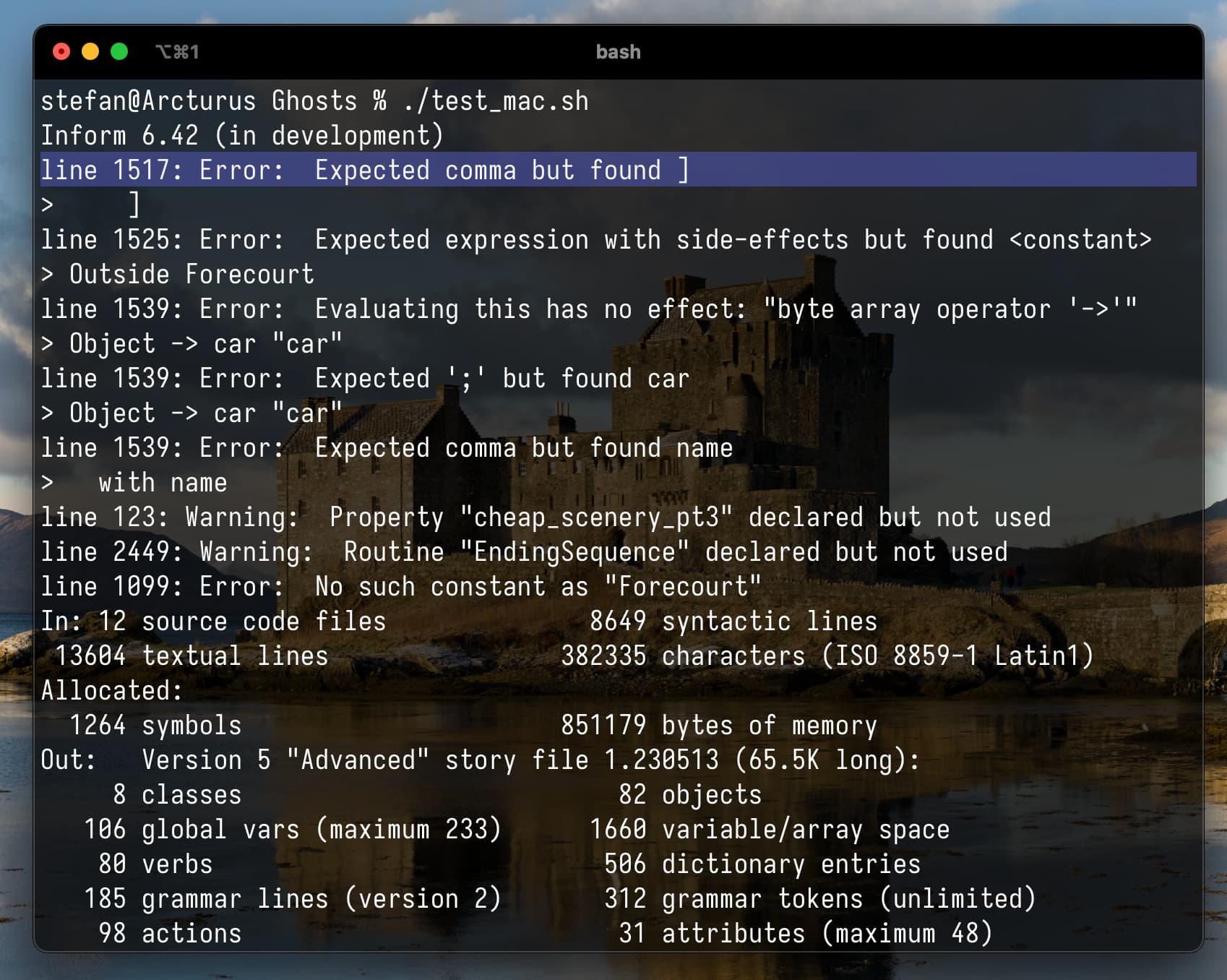
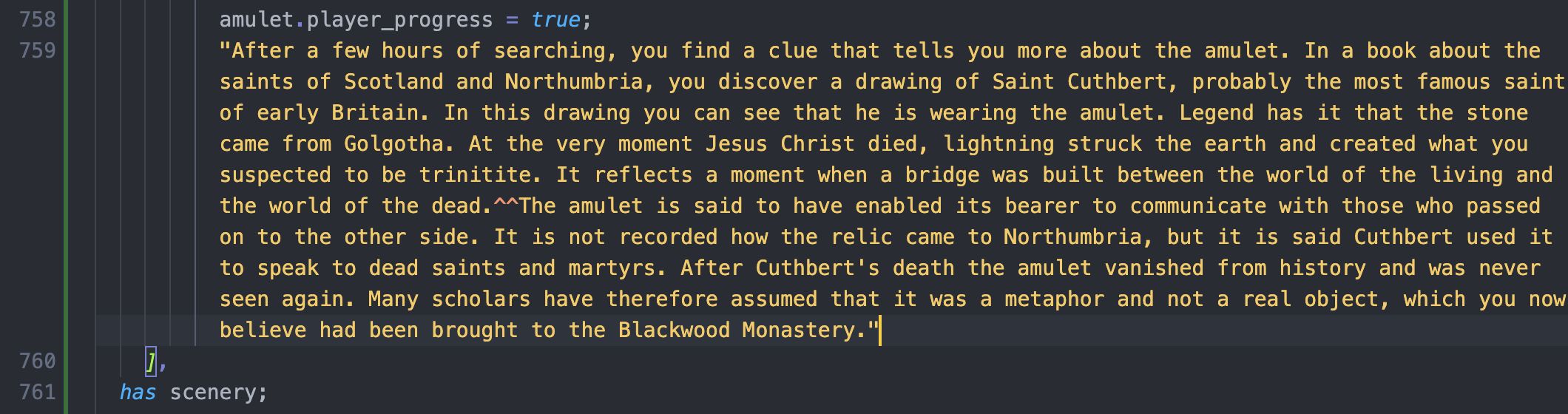
While what it means is the missing semicolon in line 759.
I am using the “in development” compiler and I compile it myself but it’s just a regular compilation with no unusual flags involved, just as you compile a plain C program with either GCC or Clang. And that’s probably important to know a well: the bug exists in my main development system, which is 64-bit Debian based (using GCC) but also on my mobile workstation, which is an Apple M1 MacBook Pro run with MacOS Ventura, where I am using Clang to compile the compiler itself.