I’m trying to create some comparisons of my system Rez vs the systems I see it mainly competing with: Twine (Harlowe), Twine (SugarCube), Twine (Snowman), Ink, and ChoiceScript.
– Update: Based on feedback so far I’ve decided the most pragmatic thing is to just drop the idea until such time as I can create something rigorous.
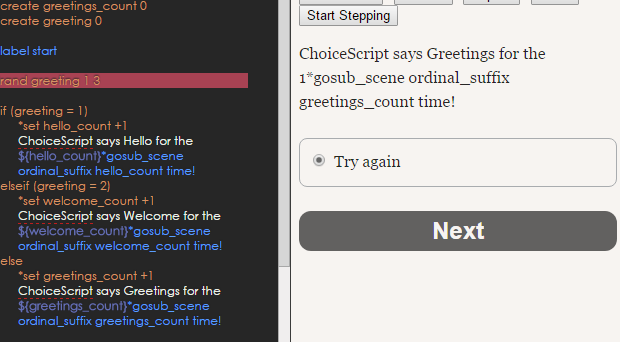
I can only speak for SugarCube, but hum… you’re often going to get some redundancy or actual errors within your code. Like $args[0] being deprecated (and the proper form being indicated in the documentation) in widgets…
For example, a simpler and more correct widgets could be reduced to this amount of lines:
<<widget "ordinal">>
<<if [11, 12, 13].includes($args[0] % 100) or not [1, 2, 3].includes($args[0] % 10)>>
<<set _suffix to "th">>
<<elseif $args[0] % 10 is 1>><<set _suffix to "st">>
<<elseif $args[0] % 10 is 2>><<set _suffix to "nd">>
<<elseif $args[0] % 10 is 3>><<set _suffix to "rd">>
<</if>>
<<print $args[0] + _suffix>>
<</widget>>
And if you’ve set $greetingCounts as a full object with all the relevant properties earlier (like in StoryInit), this would be irrelevant:
<<if not $greetingCounts>><<set $greetingCounts to {}>><</if>>
<<if not $greetingCounts[$greeting]>><<set $greetingCounts[$greeting] to 0>><</if>>
As well, this line is useless:
<<set $count to $greetingCounts[$greeting]>>
When you could simply call the widgets:
<<ordinal $greetingCounts[$greeting]>>
In short: please don’t use LLMs like Claude or GPT to create bits of code. Because 99% of the time, it gives you spaghetti code that’s works but by a thin thread that would break if you try to edit it, using deprecated or removed macros/functions, or just plain wrong.
If you want fair comparison in your examples, maybe ask outright. Debugging AI code is suuuuuuuch a pain.
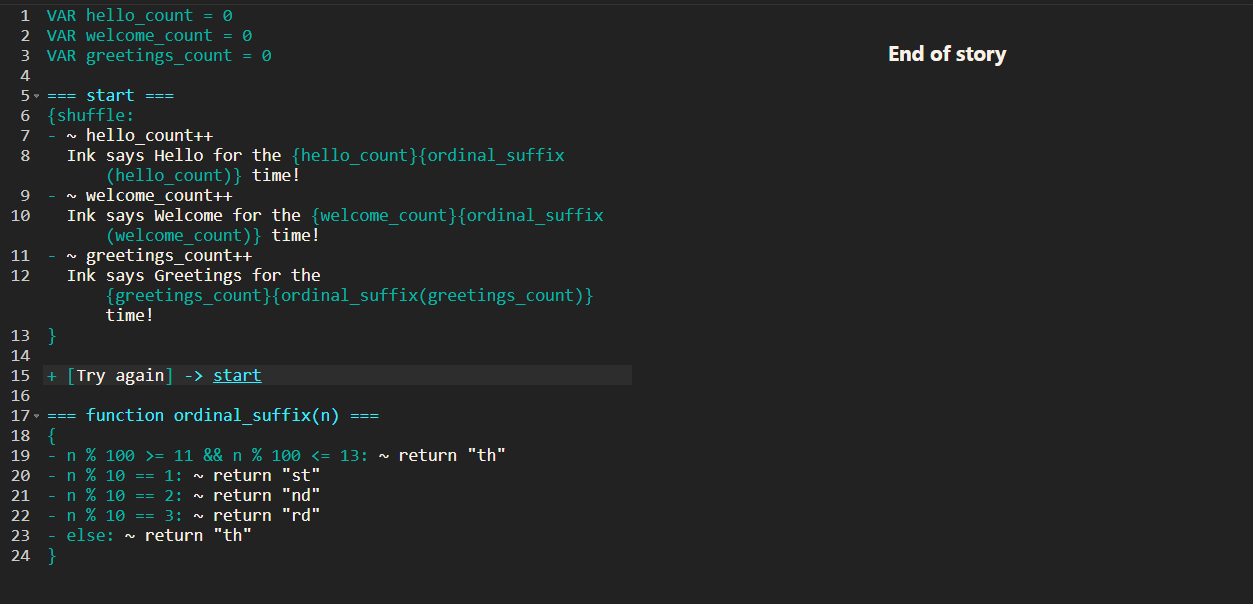
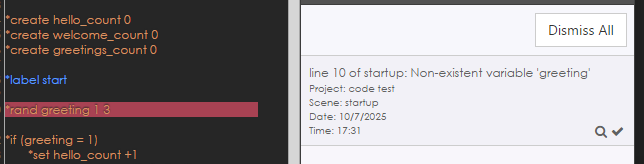
Because you don’t have a starting point for the code to run. The code essentially ends at setting the variable and THAT’s IT! Because it can’t even make a connection with your === start === passage (-> start is missing after the VAR).
Well first of all thanks for your efforts… but I hadn’t actually expected anyone would try and run them, none of those snippets are expected to be complete. E.g. the Rez example isn’t directly runnable either.
Are you… serious?
You’re trying to compare your engine with other ones, and you don’t expect people who might have some experience with those engines not to try those examples? Or people who might stumble on your page and maybe thing of testing those other engines to see for themselves?
In order to test it I’d have to learn rather more about Ink and ChoiceScript - I’ve never used either. I was really just hoping someone experienced with those systems would look it over and give a view about whether they were representative examples of an idiomatic solution in those systems. Perhaps I should drop the idea.
Yes, I’m serious. I think perhaps I created the wrong impression. I wasn’t trying to create a rigorous comparison with runnable examples but rather to give a flavour that might suggest something. Perhaps I should amend the wording or drop it altogether.
I don’t see a contradiction in wanting to be fair without necessarily creating something full-blown that might obscure the point. I’m not trying to teach people those systems. But anyway I think I have your general point, thank you.
Work, as in, “be a valid example” — yes. That’s what I was trying to get at. Work, as in, “you can copy & paste this and run it straight away” — no, that’s not what I was intending.
I’m not sure if I should just try and phrase this differently, learn more about those systems (I probably don’t have time for that), or just drop the idea entirely.
As someone who primarily uses Sugarcube and is very interested in Rez – AI generated or not, if I’m looking at these code snippets and spot obvious errors it makes me a lot less likely to switch. (Whether or not they run as-is is tangential.)
Dropping the AI code snippets is a good idea, but if you want to keep them I think there’s people here who would happily help write them in a language they’re familiar with. Maybe that’s worth considering?
Absolutely, that’s why I was I was hoping to get feedback from users of those systems to ensure that I am comparing apples to apples rather than comparing a “good” Rez example to, say, a “crappy” SugarCube one. This was a misguided effort. Maybe in future I will try again with a different angle.
FWIW, the LLMs are notoriously bad at generating code for most of the popular IF systems. Putting aside my feelings on AI for a second, there’s just not enough people using them for the training data to be reliable. Add in the fact that most of these languages are still in active development so said training data is going to be fragmented over several versions and you see the problem.
There’s also been a steady stream of people flowing in to IF community spaces asking people to help them troubleshoot their (badly) AI-generated code to the point where it was driving regular helpers away and as such had to ban that behavior, so people are already predisposed to having strong negative associations with reviewing LLM code snippets. On the flip side, people here will bend over backwards to help others out organically. Hope that helps navigate the issue going forward!