I’m likely to move this to a codeplex or sourceforge project in the future.
I’m also very likely to change the license for FyreVM to a Creative Commons license or something appropriate for wider, less restricted use.
The goal of the project is to get stateless server implementations of each platform (Inform 6, Inform 7, Hugo, TADS 3) with abstracted output layers that can be repurposed as standard HTML, AJAX, CSS, and such.
I’m working on porting FryeVM to a stateless object. We need others to pitch in to create stateless objects for the other platforms, including somehow converting Glk output to some abstract output layer.
I suggest each output abstraction use a standard service contract or schema to define itself.
If you’re interested in pitching in, let me know.
NOTE: This project is not in any way associated with my work on Textfyre. All work will be open source and share a common OSS license.
I’ve talked to Mike about porting the TADS 3 VM to something that could use Channel IO and he said it’s doable, but not trivial.
You need to first look at the I/O interfaces. All of that would need to be reconstructed to go out as a package of different types of data. It might help to look at textfyre.com/fyrevm to get an understanding of Channel IO.
The next step is to make a stateless object that can be created and destroyed on a server. The logic is simple:
Given such an object, a server process (CGI, ASP.NET, PHP, Perl, Ruby, JSP) would be able to do the rest of the “interpreter” work, which would be to format the output in HTML and return to the client.
The saved game file would be stored locally, preferably in a database, as would all commands and output, but the main work here is to create an object that implements the above interface.
That depends on if you start with the existing TADS 3 source and work from there or if you completely write a new VM from scratch. If you use the current source, I believe it’s in generic C. If you rewrite it, you can use anything you want.
Zifmia is designed to contain any VM platform built on any platform. The trick is to encapsulate the VM object with a web service in a compatible platform. Once that’s implemented, anything can talk to it.
In a normal interpreter, the virtual machine is a constantly running object. In a stateless environment, the object is created and destroyed every time. The state is maintained externally through whatever means the implementor uses. The state could be maintained by serializing/deserializing the VM object on every turn, or as suggested, by loading the game file and last game save file every turn. We can save all of the non-game data too, like the commands, the output, date, time, user information, and store that in a database.
But none of those things matter to the stateless VM. As long as it gets a valid game file and an optional save state, and a command, it can go about its business. The resulting output properties are the result, but whether a consumer actually reads them is unimportant to the VM object as well.
I am just speaking from my own experience with ZMPP, which follows a similar model (for a different reason). It’s not necessarily a trivial/cheap operation, but it does not take too much time to persist the state (in addition, you usually need to store at least one undo state, at least on Z-machine and Glulx). I think the idea of being stateless relates to scalability - if you have many players at the same time and everyone would have an in-memory session, you can’t have that many players, given the story data sizes of today’s IF. You also do not know how long players take between turns. Therefore you would at least need to swap out the state to disk if memory gets low.
The size of the save files are likely to be trivial. The game load and save load times I’ve seen for FyreVM are close to nothing. I estimate we could easily have thousands of users on a small server playing cient/server IF games.
Not to discourage your project or something, but implementing IF in a client/server architecture has already been done to a great extent. It’s called MUD (Multi User Dungeon).
Which brings me to my question: What advantages will Zimfia have over existing MUDs and Massive Multiplayer Online Games?
This is not a mud. The intent is to host games created with single player authoring tools/platforms. A user will come to a host that has implemented zifmia and see a portal. The portal allows users to upload new games and to play uploaded games. It also allows authors to develop games where the output can be implemented in HTML, JavaScript, AJAX, and CSS.
Another feature will be for testing. If the author elects to, the host can save all input and output in a database and offer reports on how testers faired in their game. So the author could login and view a particular room and see all of the commands tried in that room and all of the responses. Instead of a bunch of transcripts, they have cumulative data to respond to.
In an education setting, a teacher could host a game and use the reports to observe progress of their students.
This isn’t to say that a MUD couldn’t do all of these things, but the purpose is to allow authors to use any platform to create their games, but have one interface for output…a browser.
Some of us have been discussing about standardising a way for story files to request transcripts. If you like I can include you next time I send an email about it? My preferred way to specify these would be an extension to a blorb’s iFiction record.
I know Channel IO is your baby, but have you considered using Glk instead? After all most IF systems have been converted for use with Glk already, and Zarf has a working Glk JS implementation. It would be a lot quicker to use that and as pretty much all that would need creating now is the AJAX communication layer. You could always extend it to use Channel IO in the future.
That question seems to entirely miss the point of Channel IO. Glk is a hardened output layer. All of the windowing features are controlled by the VM and game file. With Channel IO, the output implementation is completely separate from the game file outside of labeling the output by context (main, location name, time, turn count, score, prologue, inventory, help, hints, etc).
This then leaves all of the output; the layout, the style, colors, fonts, sound, everything is done in HTML separately from the game.
Separating layout from data is one of the basic reasons for the web and HTML. I’m trying to push IF to do the same thing.
The problem here is how do you let the game control the screen? Now I know why Mike Roberts said it’s “non trivial” For example, how would you run the following on Channel IO:
One of the quibbles I had with Channel IO was this notion that the list of contexts is predefined. If you are going to abstract out the implementation details, it seems as though you should also abstract the context mechanism.
Having a means to declare a new channel along with its key properties (label, output type) would be quite useful. You could define an XML schema that provides a standard syntax, and then each game could be bundled with an XML document that sets up the default channels - probably exactly the ones that Channel IO defines.
It’s not that your list of channels is unsuitable, just that it’s a fairly narrow view of IF that’s rooted in what games have done before. It’s natural to expect most games to stick to the mold, but I would not want to see the status quo become any more ossified.
This must be bad communication on my part. The list of “channels” is somewhat hardened, but very easily changed. And the FyreVM Support file defines I7 usage for each channel, which also can easily be modified.
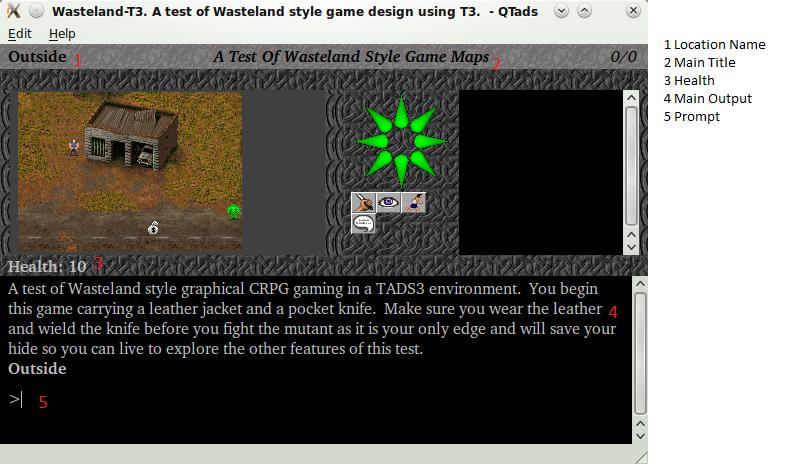
It deserves a second pass in order to allow for dynamic channel definitions, but some channels make up the “base” interface, like the main output, location name, score, turns, and prompt.
Since this conversation is in the context of zifmia, we’d probably want to figure out a way to have the base interface defined in a schema and additional, author-defined channels easily added without changing the FyreVM library.
The code is open and available. Feel free to make suggestions.
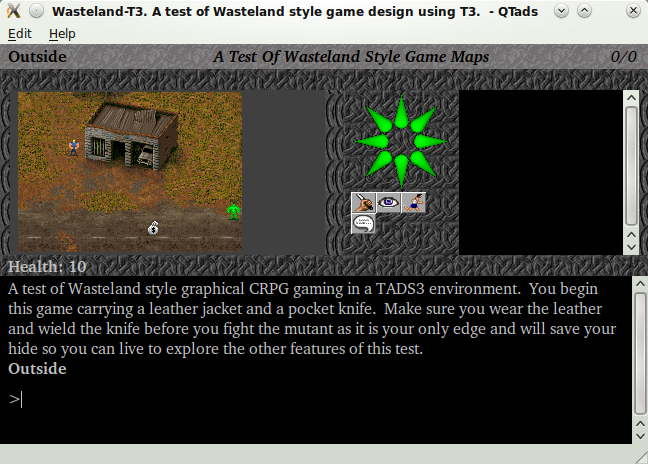
You identify the contextual elements in your game file. Then when you unpackage the output from the VM, you can place each part where it belongs on the screen. All of the graphics can be laid out and if they change, you would use channels to tell when and to what they should change. So as the map changes, a map channel might relay some text or image name that can be used to complete the layout.
It’s important to realize that the game file does not need to know about the background image (unless it changes). It doesn’t need to know about the buttons (unless they change). Anything that’s static is laid out automatically and the things that are dynamic are laid out from the output package from the VM.