That’s one of the harder points of the spec to implement – it’s not always possible to drill down to the display code and find out how character display works. (It’s basically impossible in Javascript, for example.) So not all interpreters do this reliably.
1 Like
Both Spatterlight and Garglk use the same code from CheapGlk which simply claims that they can print any Unicode character.
It would possible to check if a font actually contains a specific glyph, but it won’t be easy.
EDIT: Also, the gestalt call does not specify the style used, so I guess it will only apply to the current style with the current hints in the current window.
1 Like
If you decide to go for the path of supplying a font file with your game, you can check font support for specific Unicode characters at fileformat.info site.
Here are checks for the three Unicode characters I have seen in this discussion:
ANCHOR (U+2693) Font Support
BALLOT BOX WITH X (U+2612) Font Support
CHECK MARK (U+2713) Font Support
1 Like
That’s unfortunate. I’ve been relying on that gestalt to e.g. decide between — and -- for an em-dash.
1 Like
Well, I better implement it then.
3 Likes
Some day my game that uses ◰ ◱ ◲◳◼▲ will be published! Seriously, when I first started coding Inform and didn’t understand about interpreter compatibility, I created a puzzle using those characters and was horrified when it didn’t reproduce in Gargoyle.
1 Like
This is by far the most reliable option, as things stand. Or give the player a meta command ASCII ON/OFF, and remind them that if the game output looks like garbage, try ASCII ON.
5 Likes
I’d add this option for any game with unpronounceable characters for accessibility.
An extension I have lying around that I haven’t felt sure was useful enough to publish implements the strategy Phil and Andrew discuss above: it has a long list of say phrases like to say dash: say "[if using-unicode is true]–[else]--[end if]". The supposition was there’d be a question up front displaying the ones used and asking the player “Do you see any question marks or missing characters above?” (this would come after the “Are you using a screenreader?” question.)
Putting the player in the loop seemed like the only safe bet.
4 Likes
Perhaps surprisingly, the Z-machine can produce these characters, using “font 3”. I suspect more interpreters support this than the Unicode version, since it’s part of the spec and up to the terp rather than the font.
I think Bocfel, the Z-machine interpreter in Gargoyle, uses unicode to simulate font 3, so if the glyphs are missing in the default font, they will be missing in Bocfel as well.
1 Like
it’s not always possible to drill down to the display code and find out how character display works. (It’s basically impossible in Javascript, for example.)
I know nothing of Javascript, but is there no way to draw two characters (where one is the known “character not found” character) as images and then compare the image data?
CanvasRenderingContext2D.getImageData() seems like it should do the trick.
That sounds like a nightmare solution, honestly.
1 Like
It seems to be the preferred way to do it on iOS, and it seems to work fine in Spatterlight. But I guess Canvas works differently.
1 Like
Yes, this is correct.
It’d be nice getting this in Gargoyle, too, certainly. But since there are, generally, multiple fonts in use (monospace and proportional at least, and at the extreme, Gargoyle can use 8 completely separate fonts); so how would this work when different fonts have different coverages?
On the direct topic, and related to the linked topic in the first post, I’ve been working on font substitution in Gargoyle. At least for a first cut, the best option I found is to use GNU Unifont as a fallback font, and include it with Gargoyle. This has wide coverage of Unicode (not all, as that’s impossible in a single font), and at the moment I don’t want to deal with the possibility of shipping a bunch of different fonts, such as the Noto family, to get better coverage. A single font that does fallback is better than nothing, at least! Plus I’ve added the ability for users to specify their own fallback fonts, so if they want to slot some Noto fonts in, they can. The result looks like this (sample from Zarf’s Glulx Unicode test):
Gargoyle before substitution:
![]()
Using Unifont as the fallback:
![]()
Using a user-specified Noto Serif Hebrew as a fallback:
![]()
(I conveniently cut off the part noting that the aleph is in the wrong place: that’s a future issue to deal with…)
Unifont is very utilitarian, but it does work. The more glyphs that are missing, though, the worse things get, but it shouldn’t be worse than the question marks Gargoyle currently uses.
3 Likes
Gargoyle can use 8 completely separate fonts); so how would this work when different fonts have different coverages?
The way I implemented it, it checks if the font used by the current window style can print it. Or if there is no current window style, the normal buffer style.
EDIT: Although that is a bit overkill in Spatterlight, as the OS will look through every installed font for missing glyphs, so the answer will be the same for every font.
Not a Mac developer and I apologize in advance for naivete, but would this other approach to test if a unicode character is available using CTFontGetGlyphsForCharacters work?
That will check if a glyph is available in the font, but if you try to print a glyph that is missing in the current font, the OS might substitute it from another installed font that has it, so it won’t actually tell wether the glyph can be printed or not.
It might be possible to get a list of all installed fonts and iterate through that, but I don’t know how.
1 Like
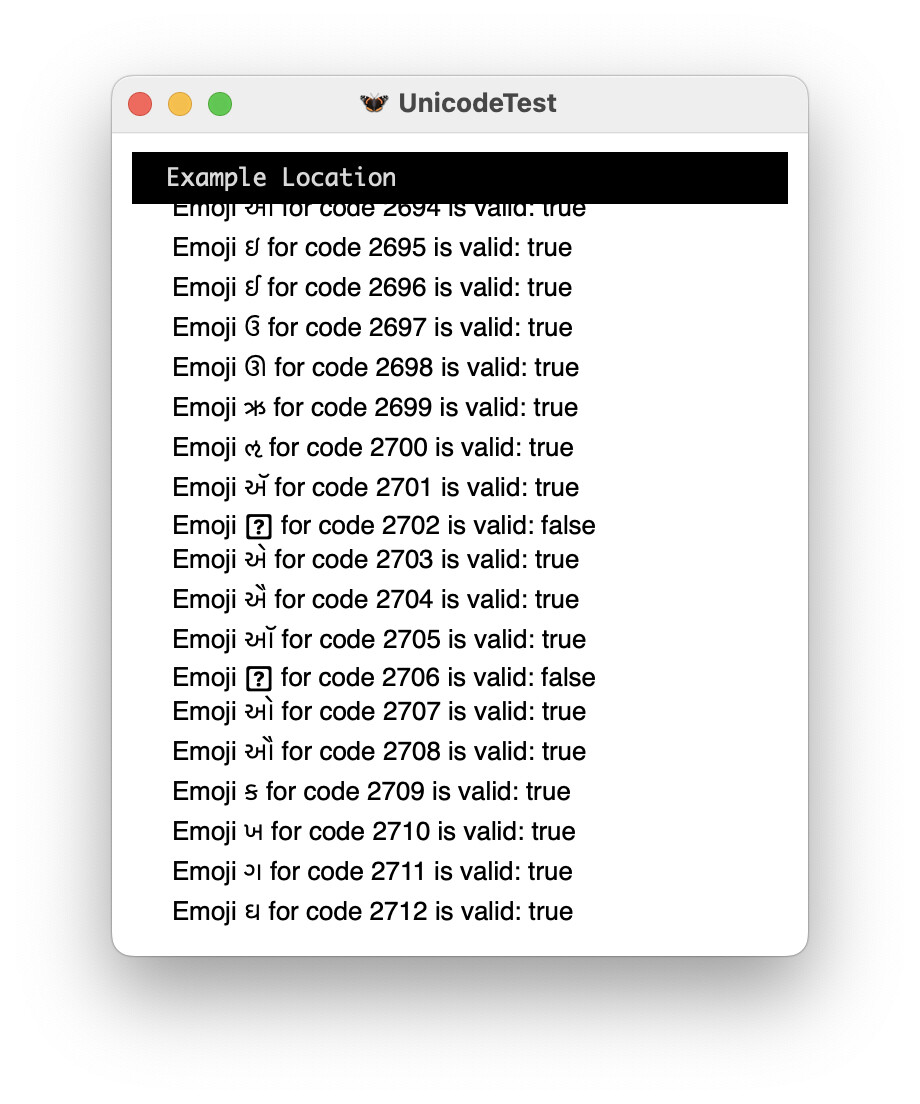
Seems to be working in Spatterlight now. Unfortunately, unlike the built-in Inform IDE interpreter (pictured below), it won’t print emojis, and I’m not sure why.

Inform 7 source below. Note that [Unicode N] won’t work, so I had to roll my own.
"UnicodeTest" by Administrator
Example Location is a room.
To decide if unicode character (N - a number) is printable:
(- (glk_gestalt(gestalt_CharOutput, {N}) ~= gestalt_CharOutput_CannotPrint) -).
To say (N - a number) as uni:
(- glk_put_char_uni({N}); -).
When play begins:
repeat with N running from 2612 to 2713:
say "Emoji [N as uni] for code [N] is valid: ";
if unicode character N is printable:
say "true";
otherwise:
say "false";
say line break.
2 Likes
Given a say N as uni phrase like the above, you can even assign a character corresponding to something above 65535 to a text and it’ll work, up to a point.
let t1 be "[128521 as uni]";
say t1; [works]
The point beyond which it’ll fail is if it gets copied to a different text: the top 16 bits get stripped.
let t2 be "[t1]";
say t2; [ fails: tries to output 0xF609, which is in a private use area ]
But if you add the following, it works (code is for 10.1; the equivalent for 9.3 works there, too):
Include (-
Constant TEXT_TY_Storage_Flags = BLK_FLAG_MULTIPLE + BLK_FLAG_WORD;
-) replacing "TEXT_TY_Storage_Flags";
…or at least I haven’t seen it cause problems. But I haven’t tried it beyond the proof of concept and it’s probably a terrible idea.
2 Likes