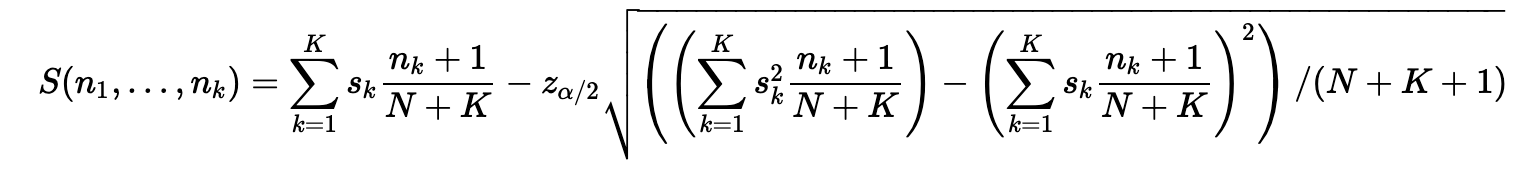This post is kinda long.
tl;dr: IMO, next year, ECTOCOMP should just use the raw score, instead of Itch’s adjusted score.
IFComp uses a simple weighted average
IFComp doesn’t have its own formula; IFComp simply uses the weighted average (Itch’s “raw score”).
You can see IFComp’s system by looking at the raw data in JSON. https://ifcomp.org/comp/2024/json
Looking at The Bat, we see these scores:
1: 0
2: 0
3: 0
4: 0
5: 2
6: 5
7: 7
8: 23
9: 36
10: 16
That’s 89 votes cast.
10*16 + 9*36 + 8*23 + 7*7 + 6*5 + 5*2 = 757
757 / 89 = 8.51
And that’s exactly the average_score shown in the UI, used for ranking, and displayed in the JSON.
ECTOCOMP should do the same, I claim.
IFDB uses Starsort, but I don’t think competitions should use it
On IFDB, we determine the games with the highest ratings using Evan Miller’s formula, which we call “Starsort”.
(Starsort is my naming; Evan Miller doesn’t give it a name. Note that the MathJax JS on his page messes up the equation in Google Chrome, so you might prefer to read the page in Firefox or Safari.)
We used to sort by average rating, but this would tend to rank games with just one perfect 5-star rating above games with dozens of 5-star ratings and a few 4-star ratings. Evan Miller’s formula sorts by our confidence in the game, by adding five “fake” ratings to the average (one 1-star, one 2-star, one 3-star, one 4-star, and one 5-star rating) and subtracting the standard deviation from the result.
Starsort is too complex for competitions
But I think Starsort isn’t good for competitions, partly because it’s so complex. Look at this monstrosity! Competition algorithms should be simple and easy to understand, to ensure that everyone can believe in its fairness.
Starsort is intended to solve a different problem
The problem Starsort is intended to solve is to avoid highlighting games that we’re “uncertain” of. A game with a single 5-star rating is promising, but if someone predicted that it would turn out to be one of the best games in the entire IFDB, I’d be very, very skeptical. By adding fake reviews and subtracting the standard deviation, we’re effectively “penalizing” a game with a small number of positive reviews.
But, in score voting, we normally don’t want games with a small number of votes to be penalized. Instead, we should simply trust the raw score.
We just need each game to have “enough votes”
Instead, to combat cases where games have a widely different number of votes, the organizers should just try very, very hard to ensure that every game gets a certain minimum number of votes.
I think English ECTOCOMP already has enough votes to simply trust the raw score
In “Le Grand Guignol - English”, “Museum of Paranormal Phenomena” received 9 votes. “do not let your left hand know” received 23 votes, 2.5x more. That’s actually a better ratio than IFComp 2024, where the most-voted game received more than 8x the votes of the least-voted game.
I don’t know what an ideal target ratio of most/least votes is, but I’d guess that at 2.5x, “Le Grand Guignol - English” is probably already at the target.
“La Petite Mort - English” is even more balanced, with “Your Little Haunting” getting 15 votes and “Die Another Day” getting 27, only 1.8x more.